Проектирование схемы для наблюдаемости
Мы рекомендуем пользователям всегда создавать собственную схему для логов и трейсов по следующим причинам:
- Выбор первичного ключа - По умолчанию схемы используют
ORDER BY, который оптимизирован для конкретных паттернов доступа. Вероятно, что ваши паттерны доступа не будут совпадать с этим. - Извлечение структуры - Пользователи могут захотеть извлечь новые столбцы из существующих столбцов, например из столбца
Body. Это можно сделать с помощью материализованных столбцов (а в более сложных случаях - с помощью материализованных представлений). Это требует изменений в схеме. - Оптимизация карт - Схемы по умолчанию используют тип Map для хранения атрибутов. Эти столбцы позволяют хранить произвольные метаданные. Хотя это важная возможность, так как метаданные из событий часто не определяются заранее и, следовательно, не могут быть хранены в строго типизированной базе данных, такой как ClickHouse, доступ к ключам карты и их значениям не является таким эффективным, как доступ к обычному столбцу. Мы решаем эту проблему, изменяя схему и обеспечивая, чтобы наиболее часто запрашиваемые ключи карты были столбцами верхнего уровня - см. "Извлечение структуры с помощью SQL". Это требует изменения схемы.
- Упрощение доступа к ключам карты - Доступ к ключам в картах требует более многословного синтаксиса. Пользователи могут смягчить это с помощью псевдонимов. См. "Использование псевдонимов" для упрощения запросов.
- Вторичные индексы - Схема по умолчанию использует вторичные индексы для ускорения доступа к картам и ускорения текстовых запросов. Как правило, они не требуются и требуют дополнительного места на диске. Их можно использовать, но их следует протестировать, чтобы убедиться, что они необходимы. См. "Вторичные индексы / Индексы пропуска данных".
- Использование кодеков - Пользователи могут захотеть настроить кодеки для столбцов, если они понимают ожидаемые данные и имеют доказательства того, что это улучшает сжатие.
Мы подробно описываем каждое из вышеуказанных случаев использования ниже.
Важно: Хотя пользователям рекомендуется расширять и изменять свою схему для достижения оптимального сжатия и производительности запросов, им следует придерживаться именования столбцов схемы OTel, где это возможно. Плагин Grafana для ClickHouse предполагает наличие некоторых основных столбцов OTel для помощи в создании запросов, таких как Timestamp и SeverityText. Обязательные столбцы для логов и трейсов задокументированы здесь [1][2] и здесь соответственно. Вы можете выбрать изменение имен этих столбцов, переопределив значения по умолчанию в конфигурации плагина.
Извлечение структуры с помощью SQL
При приеме структурированных или неструктурированных логов пользователям часто нужна возможность:
- Извлечение столбцов из строковых массивов. Запросы к ним будут быстрее, чем использование строковых операций во время выполнения запроса.
- Извлечение ключей из карт. Схема по умолчанию помещает произвольные атрибуты в столбцы типа Map. Этот тип предоставляет возможность без схемы, что имеет преимущество в том, что пользователям не нужно заранее определять столбцы для атрибутов при создании логов и трейсов - часто это невозможно при сборе логов из Kubernetes и желании сохранить метки подов для дальнейшего поиска. Доступ к ключам карты и их значениям медленнее, чем запрос по обычным столбцам ClickHouse. Следовательно, извлечение ключей из карт в корневые столбцы таблицы часто желательно.
Рассмотрим следующие запросы:
Предположим, мы хотим сосчитать, какие URL пути получают больше всего POST запросов, используя структурированные логи. JSON массив хранится в столбце Body как строка. Кроме того, он может быть также хранится в столбце LogAttributes как Map(String, String), если пользователь включил json_parser в сборщике.
Предположим, что LogAttributes доступен, запрос для подсчета, какие URL пути сайта получают больше всего POST запросов:
Обратите внимание на использование синтаксиса карты здесь, например, LogAttributes['request_path'], и path функции для удаления параметров запроса из URL.
Если пользователь не включил парсинг JSON в сборщике, то LogAttributes будет пустым, что заставит нас использовать JSON функции для извлечения столбцов из строкового Body.
Мы обычно рекомендуем пользователям выполнять парсинг JSON в ClickHouse для структурированных логов. Мы уверены, что ClickHouse - самая быстрая реализация разбора JSON. Однако мы понимаем, что пользователи могут захотеть отправить логи в другие источники и не иметь этой логики в SQL.
Теперь рассмотрим то же самое для неструктурированных логов:
Аналогичный запрос для неструктурированных логов требует использования регулярных выражений через extractAllGroupsVertical функцию.
Увеличенная сложность и стоимость запросов для разбора неструктурированных логов (обратите внимание на разницу в производительности) - вот почему мы рекомендуем пользователям всегда использовать структурированные логи, когда это возможно.
Вышеуказанный запрос можно оптимизировать для использования словарей регулярных выражений. См. Использование словарей для получения дополнительной информации.
Оба этих случая использования могут быть решены с помощью ClickHouse, перемещая логику вышеуказанных запросов на время вставки. Мы рассмотрим несколько подходов ниже, подчеркивая, когда каждый из них подходит.
Пользователи также могут выполнять обработку, используя процессоры и операторы OTel Collector, как описано здесь. В большинстве случаев пользователи обнаружат, что ClickHouse значительно более эффективно использует ресурсы и быстрее, чем процессоры сборщика. Основным недостатком выполнения всей обработки событий в SQL является зависимость вашего решения от ClickHouse. Например, пользователи могут захотеть отправить обработанные логи в альтернативные пункты назначения из сборщика OTel, такие как S3.
Материализованные столбцы
Материализованные столбцы предлагают самое простое решение для извлечения структуры из других столбцов. Значения таких столбцов всегда вычисляются во время вставки и не могут быть указаны в командах INSERT.
Материализованные столбцы накладывают дополнительные накладные расходы на хранение, поскольку значения извлекаются в новые столбцы на диске во время вставки.
Материализованные столбцы поддерживают любое выражение ClickHouse и могут использовать любые аналитические функции для обработки строк (включая регулярные выражения и поиск) и url-адресов, выполняя преобразования типов, извлечение значений из JSON или математические операции.
Мы рекомендуем использовать материализованные столбцы для базовой обработки. Они особенно полезны для извлечения значений из карт, повышения их до корневых столбцов и выполнения преобразования типов. Они часто наиболее полезны при использовании в очень простых схемах или в сочетании с материализованными представлениями. Рассмотрим следующую схему для логов, из которых JSON был извлечен в столбец LogAttributes сборщиком:
Эквивалентная схема для извлечения с использованием JSON функций из строкового Body представлена здесь.
Наши три материализованных столбца извлекают запрашиваемую страницу, тип запроса и домен реферера. Они получают доступ к ключам карты и применяют функции к их значениям. Наш последующий запрос значительно быстрее:
Материализованные столбцы по умолчанию не будут возвращены в SELECT *. Это необходимо для сохранения инварианта, что результат SELECT * можно всегда вставить обратно в таблицу с помощью INSERT. Это поведение можно отключить, установив asterisk_include_materialized_columns=1, и оно может быть включено в Grafana (см. Дополнительные настройки -> Пользовательские настройки в конфигурации источника данных).
Материализованные представления
Материализованные представления предоставляют более мощный способ применения SQL-фильтрации и преобразований к логам и трейсам.
Материализованные представления позволяют пользователям перенести стоимость вычислений с времени выполнения запросов на время вставки. Материализованное представление ClickHouse - это просто триггер, который выполняет запрос над блоками данных, когда они вставляются в таблицу. Результаты этого запроса вставляются во вторую "целевую" таблицу.
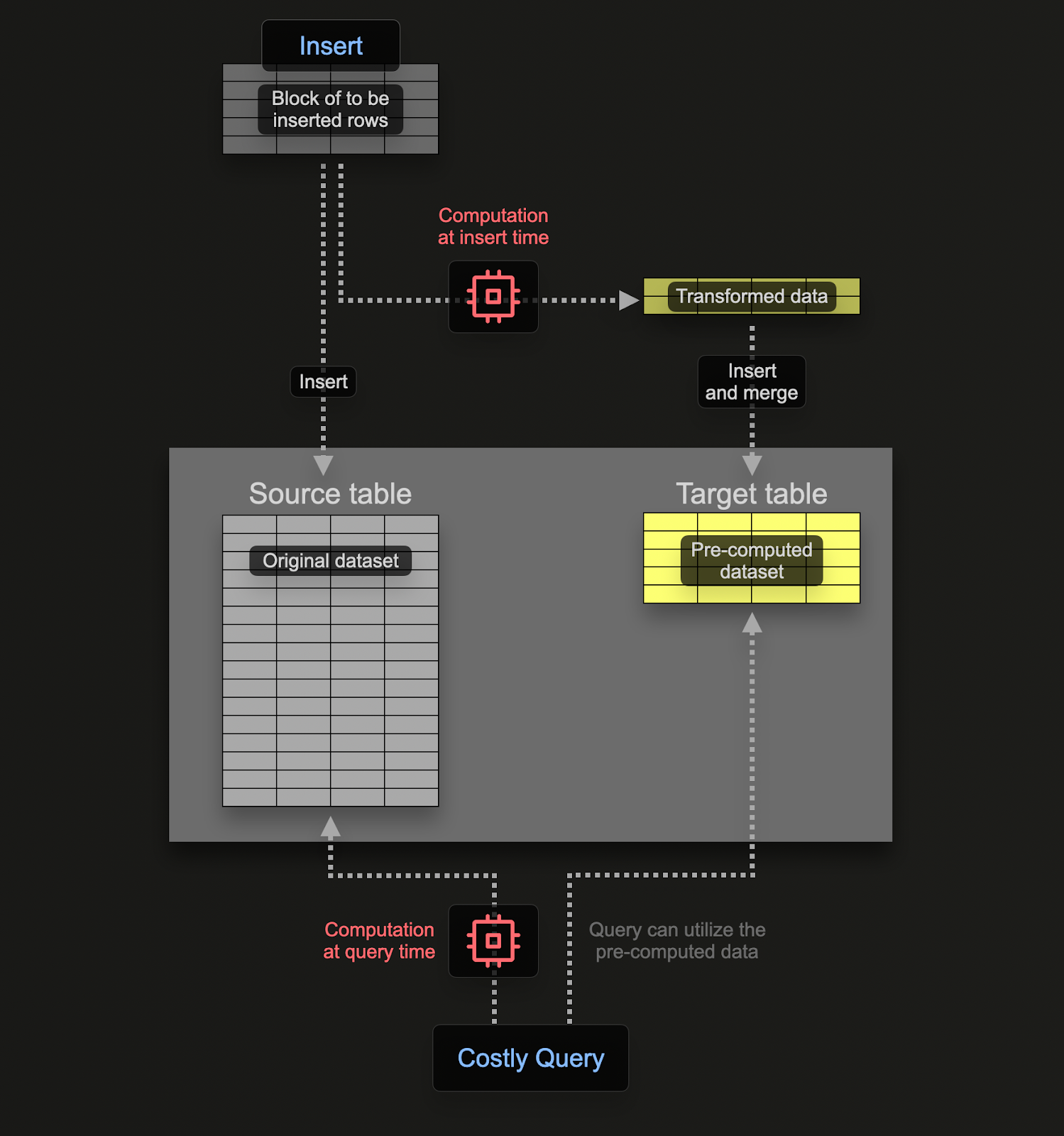
Материализованные представления в ClickHouse обновляются в реальном времени, когда данные поступают в таблицу, на основе которой они созданы, функционируя более как постоянно обновляющиеся индексы. В отличие от этого, в других базах данных материализованные представления обычно являются статическими снимками запроса, которые необходимо обновлять (аналогично обновляемым материализованным представлениям ClickHouse).
Запрос, связанный с материализованным представлением, теоретически может быть любым запросом, включая агрегацию, хотя существуют ограничения с соединениями. Для преобразований и фильтрации, необходимых для логов и трейсов, пользователи могут рассматривать любое выражение SELECT как возможное.
Пользователи должны помнить, что запрос - это всего лишь триггер, выполняющийся над строками, которые вставляются в таблицу (исходную таблицу), а результаты отправляются в новую таблицу (целевую таблицу).
Чтобы убедиться, что мы не сохраняем данные дважды (в исходной и целевой таблицах), мы можем изменить таблицу исходной таблицы на движок таблицы Null, сохраняя оригинальную схему. Наши сборщики OTel будут продолжать отправлять данные в эту таблицу. Например, для логов таблица otel_logs становится:
Движок таблицы Null представляет собой мощную оптимизацию - рассматривайте его как /dev/null. Эта таблица не будет хранить никаких данных, но все прикрепленные материализованные представления будут по-прежнему выполняться над вставляемыми строками перед тем, как они будут отброшены.
Рассмотрим следующий запрос. Он преобразует наши строки в формат, который мы хотим сохранить, извлекая все столбцы из LogAttributes (мы предполагаем, что это было установлено сборщиком с использованием оператора json_parser), устанавливая SeverityText и SeverityNumber (на основе простых условий и определения этих столбцов). В этом случае мы также выбираем только те столбцы, которые мы знаем, что будут заполнены - игнорируя столбцы, такие как TraceId, SpanId и TraceFlags.
Мы также извлекаем столбец Body выше - на случай, если дополнительные атрибуты будут добавлены позднее, которые не будут извлечены нашим SQL. Этот столбец должен хорошо сжиматься в ClickHouse и будет редко запрашиваться, таким образом, не влияя на производительность запроса. Наконец, мы уменьшаем Timestamp до DateTime (чтобы сэкономить место - см. "Оптимизация типов") с приведением типа.
Обратите внимание на использование условных операторов выше для извлечения SeverityText и SeverityNumber. Эти функции чрезвычайно полезны для формулирования сложных условий и проверки, установлены ли значения в картах - мы наивно предполагаем, что все ключи существуют в LogAttributes. Мы рекомендуем пользователям ознакомиться с ними - они ваши помощники в разборе логов в дополнение к функциям для работы с null значениями!
Нам нужна таблица для получения этих результатов. Ниже представлена целевая таблица, соответствующая вышеуказанному запросу:
Типы, выбранные здесь, основаны на оптимизациях, обсуждаемых в "Оптимизация типов".
Обратите внимание, как мы радикально изменили нашу схему. На самом деле, пользователи, вероятно, также захотят сохранить столбцы Trace, а также столбец ResourceAttributes (это обычно содержит метаданные Kubernetes). Grafana может использовать столбцы Trace для предоставления функциональности связывания между логами и трейсами - см. "Использование Grafana".
Ниже мы создаем материализованное представление otel_logs_mv, которое выполняет вышеуказанный выбор для таблицы otel_logs и отправляет результаты в otel_logs_v2.
Эта вышеуказанная структура визуализируется ниже:
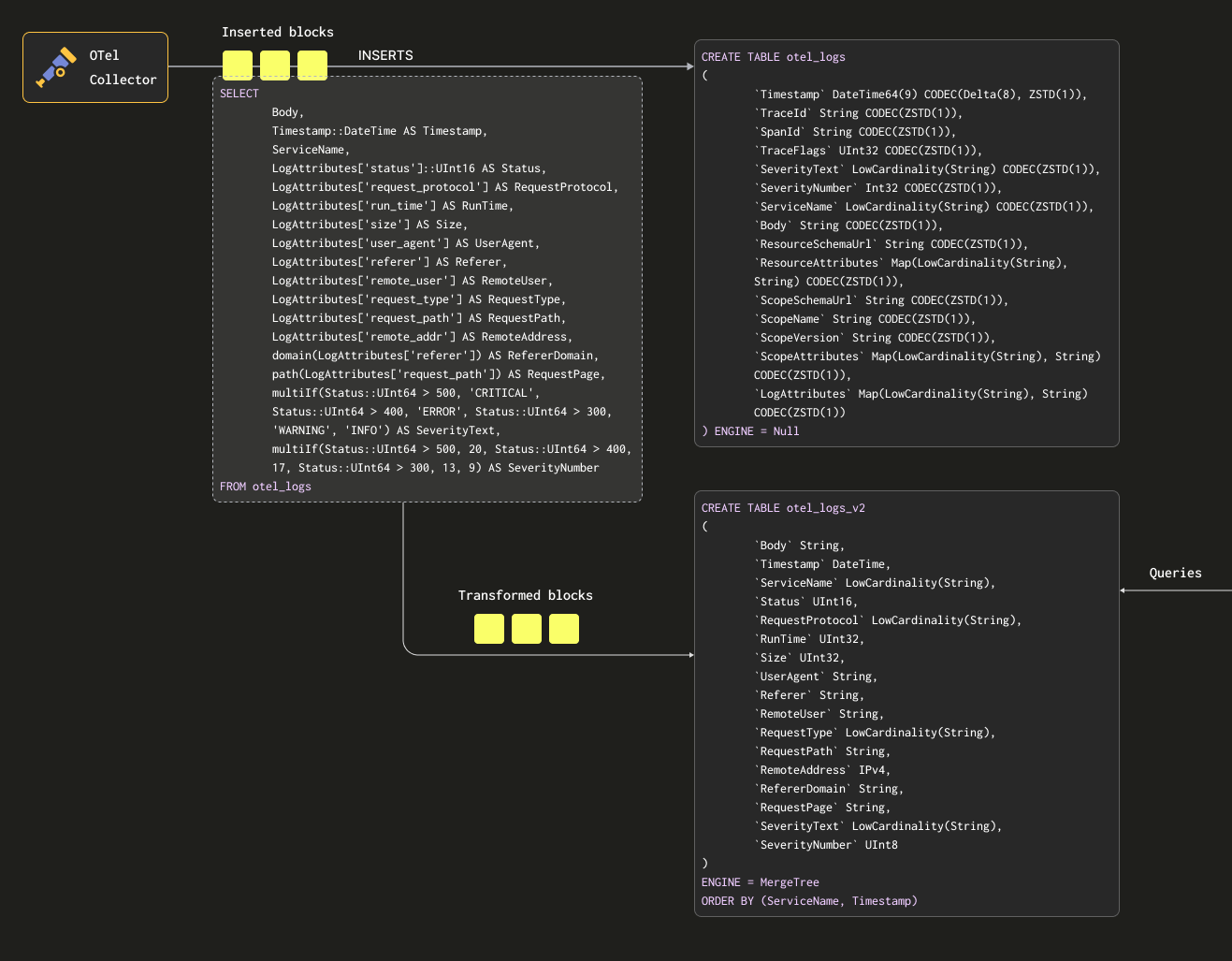
Если мы теперь перезапустим конфигурацию сборщика, используемую в "Экспорт в ClickHouse", данные появятся в otel_logs_v2 в нашем желаемом формате. Обратите внимание на использование типизированных функций извлечения JSON.
Эквивалентное материализованное представление, которое зависит от извлечения столбцов из столбца Body с использованием JSON функций, показано ниже:
Будьте осторожны с типами
Вышеуказанные материализованные представления полагаются на неявное приведение типов - особенно в случае использования карты LogAttributes. ClickHouse часто автоматически преобразует извлеченное значение в тип целевой таблицы, уменьшая необходимый синтаксис. Однако мы рекомендуем пользователям всегда тестировать свои представления, используя оператор SELECT представления с оператором INSERT INTO с целевой таблицей, использующей ту же схему. Это должно подтвердить, что типы обрабатываются корректно. Особое внимание следует уделить следующим случаям:
- Если ключ не существует в карте, будет возвращена пустая строка. В случае числовых значений пользователям придется сопоставить их с подходящим значением. Это можно сделать с помощью условных операторов, например,
if(LogAttributes['status'] = ", 200, LogAttributes['status']), или функций приведения типов, если допустимы значения по умолчанию, например,toUInt8OrDefault(LogAttributes['status'] ). - Некоторые типы не всегда будут приводиться, например, строковые представления чисел не будут приводиться в значения перечислений.
- Функции извлечения JSON возвращают значения по умолчанию для своего типа, если значение не найдено. Убедитесь, что эти значения имеют смысл!
Избегайте использования Nullable в ClickHouse для данных наблюдаемости. Редко требуется в логах и трейсах различать пустые и null. Эта функция накладывает дополнительные накладные расходы на хранение и отрицательно влияет на производительность запросов. См. здесь для получения дополнительных сведений.
Выбор первичного (упорядочивающего) ключа
После того, как вы извлекли необходимые столбцы, вы можете начать оптимизировать ваш упорядочивающий/первичный ключ.
Некоторые простые правила могут быть применены для выбора упорядочивающего ключа. Следующие правила иногда могут конфликтовать, поэтому рассматривайте их в порядке очередности. Пользователи могут определить ряд ключей в этом процессе, при этом обычно достаточно 4-5:
- Выберите столбцы, которые соответствуют вашим общим фильтрам и паттернам доступа. Если пользователи обычно начинают расследование в области наблюдаемости, отфильтровывая по конкретному столбцу, например, имени пода, этот столбец будет часто использоваться в условиях
WHERE. Приоритизируйте их включение в ваш ключ по сравнению с теми, которые используются реже. - Предпочитайте столбцы, которые помогают исключить большой процент общих строк при фильтрации, уменьшая количество данных, которые необходимо прочитать. Имена сервисов и коды состояния обычно являются хорошими кандидатами - в последнем случае только если пользователи фильтруют значения, которые исключают большинство строк, например, фильтрация по 200-ым будет в большинстве систем соответствовать большинству строк, в сравнении с 500 ошибками, которые будут соответствовать небольшой подгруппе.
- Предпочитайте столбцы, которые, вероятно, будут высоко коррелированы с другими столбцами в таблице. Это поможет обеспечить их соседнее хранение, улучшая сжатие.
- Операции
GROUP BYиORDER BYдля столбцов в упорядочивающем ключе могут быть выполнены более эффективно в отношении памяти.
Определив подмножество столбцов для упорядочивающего ключа, их необходимо объявить в определенном порядке. Этот порядок может значительно повлиять как на эффективность фильтрации по столбцам второго ключа в запросах, так и на коэффициент сжатия для файлов данных таблицы. В общем, лучше всего упорядочивать ключи в порядке возрастания кардинальности. Это следует сбалансировать с тем фактом, что фильтрация по столбцам, которые появляются позже в упорядочивающем ключе, будет менее эффективной, чем фильтрация по тем, которые появляются раньше в кортеже. Балансируйте эти поведения и учитывайте свои паттерны доступа. Важнейшее, тестируйте варианты. Для более глубокого понимания упорядочивающих ключей и того, как их оптимизировать, мы рекомендуем эту статью.
Мы рекомендуем решить ваши упорядочивающие ключи, как только вы структурировали свои логи. Не используйте ключи в атрибутных картах для упорядочивающего ключа или выражений извлечения JSON. Убедитесь, что ваши упорядочивающие ключи являются корневыми столбцами в вашей таблице.
Использование карт
Ранее приведенные примеры показывают использование синтаксиса карты map['key'] для доступа к значениям в столбцах Map(String, String). Кроме того, доступные специализированные функции ClickHouse map functions позволяют фильтровать или выбирать эти столбцы.
Например, следующий запрос определяет все уникальные ключи, доступные в столбце LogAttributes, используя mapKeys функцию, за которой следует groupArrayDistinctArray функция (комбинатор).
Мы не рекомендуем использовать точки в именах столбцов Map и можем объявить это использование устаревшим. Используйте _.
Использование псевдонимов
Запросы к типам карт медленнее, чем запросы к обычным столбцам - см. "Ускорение запросов". Кроме того, они более синтаксически сложные и могут быть обременительными для пользователей. Для решения этой последней проблемы мы рекомендуем использовать столбцы Alias.
Столбцы ALIAS вычисляются во время запроса и не хранятся в таблице. Поэтому невозможно ВСТАВИТЬ значение в столбец такого типа. С помощью псевдонимов мы можем ссылаться на ключи карт и упрощать синтаксис, прозрачно об exposing элементы карты как обычный столбец. Рассмотрим следующий пример:
У нас есть несколько материализованных столбцов и столбец ALIAS, RemoteAddr, который получает доступ к карте LogAttributes. Теперь мы можем запрашивать значения LogAttributes['remote_addr'] через этот столбец, тем самым упрощая наш запрос, т.е.
Более того, добавление ALIAS осуществляется легко через команду ALTER TABLE. Эти столбцы доступны немедленно, например:
По умолчанию, SELECT * исключает столбцы ALIAS. Это поведение можно отключить, установив asterisk_include_alias_columns=1.
Оптимизация типов
Общие Рекомендации по ClickHouse для оптимизации типов применимы к использованию ClickHouse.
Использование кодеков
Помимо оптимизации типов, пользователи могут следовать общим рекомендациям по кодекам, когда пытаются оптимизировать сжатие для схем наблюдаемости ClickHouse.
В общем, пользователи найдут, что кодек ZSTD очень подходит для данных журналирования и трассировки. Увеличение значения сжатия от его значения по умолчанию 1 может улучшить сжатие. Однако это следует протестировать, так как более высокие значения влекут за собой большую нагрузку на CPU во время вставки. Обычно мы не видим значительного прироста от увеличения этого значения.
Более того, временные метки, хотя и выигрывают от дельта-кодирования по отношению к сжатию, показали, что они замедляют выполнение запросов, если этот столбец используется в первичном/упорядочивающем ключе. Мы рекомендуем пользователям оценить соответствующие компромиссы между сжатием и производительностью запросов.
Использование словарей
Словари являются ключевой функцией ClickHouse, предоставляющей представление данных в памяти в формате ключ-значение из различных внутренних и внешних источников, оптимизированным для запросов с супернизкой задержкой.
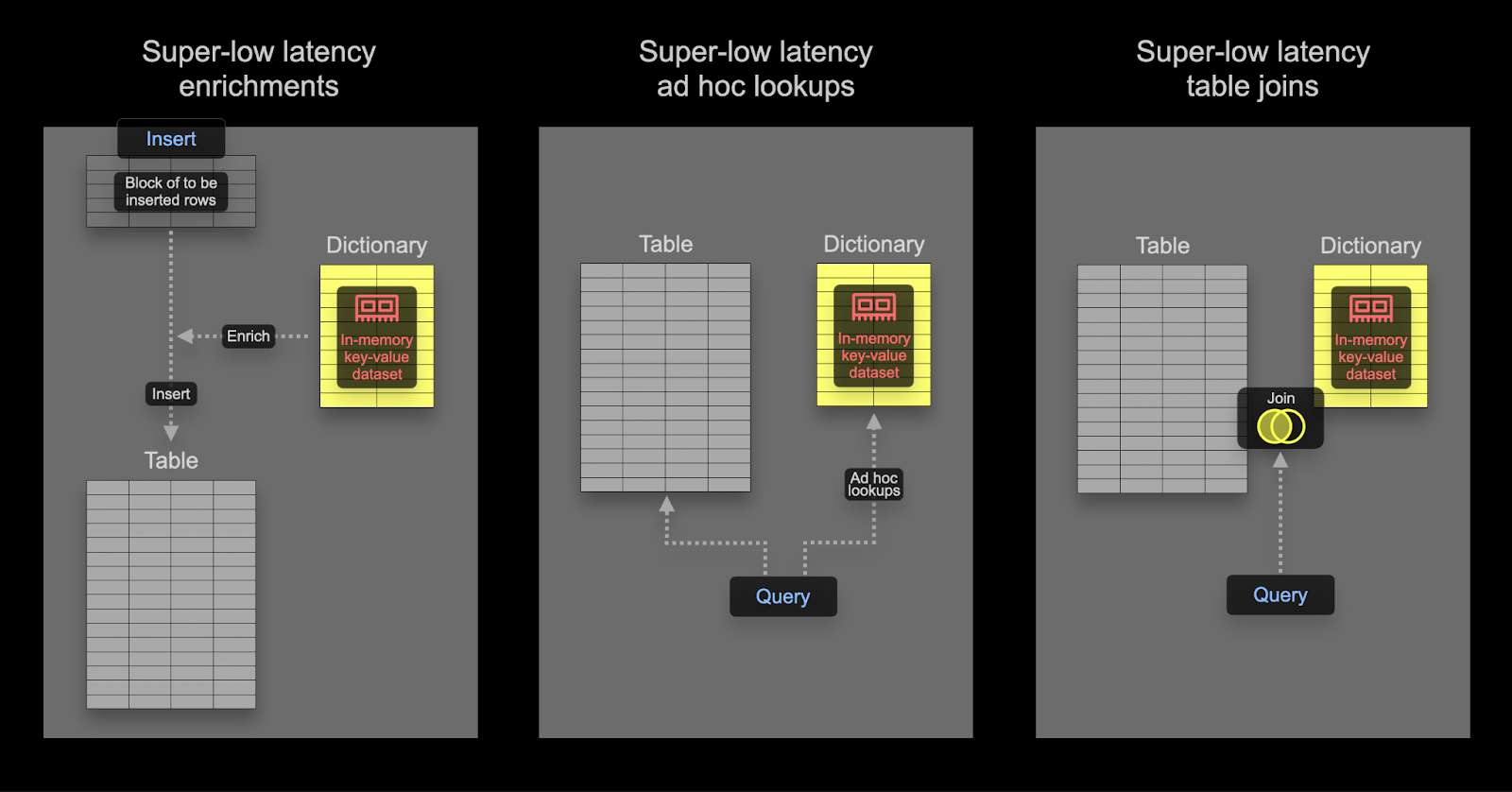
Это удобно в различных сценариях, начиная от обогащения принятых данных на лету без замедления процесса приема и улучшения производительности запросов в целом, особенно с использованием JOINs. Хотя соединения редко требуются в случаях наблюдаемости, словари всё равно могут быть удобны для целей обогащения как во время вставки, так и во время запроса. Мы приводим примеры обоих случаев ниже.
Пользователи, заинтересованные в ускорении соединений с помощью словарей, могут найти дополнительные сведения здесь.
Время вставки против времени запроса
Словари можно использовать для обогащения наборов данных во время запроса или во время вставки. Каждому из этих подходов соответствуют свои плюсы и минусы. Вкратце:
- Время вставки - Это обычно подходит, если значение обогащения не меняется и существует во внешнем источнике, который можно использовать для заполнения словаря. В этом случае обогащение строки во время вставки избегает обращения к словарю во время запроса. Это происходит с потерей производительности вставки, а также с дополнительными затратами на хранилище, так как обогащенные значения будут храниться в виде столбцов.
- Время запроса - Если значения в словаре меняются часто, обращения к словарю во время запроса часто более применимы. Это избегает необходимости обновлять столбцы (и переписывать данные), если сопоставленные значения изменяются. Эта гибкость происходит за счет стоимости обращения во время запроса. Эта стоимость обычно заметна, если необходимо обратиться к многим строкам, например, используя поиск в словаре в условии фильтра. Для обогащения результатов, т.е. в
SELECT, эта нагрузка обычно незначительна.
Мы рекомендуем пользователям ознакомиться с основами словарей. Словари предоставляют таблицу поиска в памяти, из которой можно извлекать значения с использованием специализированных функций.
Для простых примеров обогащения ознакомьтесь с руководством по Словарям здесь. Ниже мы сосредоточимся на общих задачах обогащения в области наблюдаемости.
Использование IP словарей
Географическое обогащение логов и трасс с помощью значений широты и долготы, используя IP-адреса, является общим требованием наблюдаемости. Мы можем достичь этого с помощью структурированного словаря ip_trie.
Мы используем общедоступный набор данных уровня города DB-IP, предоставленный DB-IP.com на условиях лицензии CC BY 4.0.
Из README видно, что данные структурированы следующим образом:
Учитывая такую структуру, начнем с того, чтобы взглянуть на данные, используя табличную функцию url():
Чтобы упростить нашу задачу, давайте используем URL() движок таблицы, чтобы создать объект таблицы ClickHouse с нашими именами полей и подтвердить общее количество строк:
Поскольку наш словарь ip_trie требует диапазоны IP-адресов в CIDR-нотации, нам нужно преобразовать ip_range_start и ip_range_end.
Этот CIDR для каждого диапазона можно кратко вычислить с помощью следующего запроса:
В запросе выше много работы. Для интересующихся, прочитайте это отличное объяснение. В противном случае примите, что выше вычисляется CIDR для диапазона IP.
Для наших целей нам понадобятся только диапазон IP, код страны и координаты, поэтому давайте создадим новую таблицу и вставим наши данные Geo IP:
Чтобы выполнить запросы IP с низкой задержкой в ClickHouse, мы воспользуемся словарями для хранения отображения ключей и атрибутов для наших данных Geo IP в памяти. ClickHouse предоставляет структуру словаря ip_trie словаря для сопоставления наших сетевых префиксов (CIDR блочные) с координатами и кодами стран. Следующий запрос определяет словарь, используя эту компоновку и указанную выше таблицу в качестве источника.
Мы можем выбрать строки из словаря и подтвердить, что этот набор данных доступен для поиска:
Словари в ClickHouse периодически обновляются на основе данных базовой таблицы и используемой выше оговорки о времени жизни. Чтобы обновить наш Geo IP словарь, чтобы отразить последние изменения в наборе данных DB-IP, нам нужно будет просто повторно вставить данные из удаленной таблицы geoip_url в нашу таблицу geoip с преобразованиями.
Теперь, когда мы загрузили данные Geo IP в наш словарь ip_trie (который также удобно называется ip_trie), мы можем использовать его для геолокации IP. Это можно сделать с использованием dictGet() функции следующим образом:
Обратите внимание на скорость получения здесь. Это позволяет нам обогатить журналы. В этом случае мы выбрали выполнять обогащение во время запроса.
Возвращаясь к нашему первоначальному набору данных журналов, мы можем использовать вышеуказанное для агрегирования наших журналов по странам. Следующий запрос предполагает использование схемы, полученной из нашего раннего материализованного представления, которое имеет извлеченный столбец RemoteAddress.
Поскольку отображение IP на географическое местоположение может измениться, пользователи, вероятно, захотят знать, откуда был сделан запрос в момент его выполнения, а не где находится текущее географическое местоположение того же адреса. По этой причине обогащение во время индексации, вероятно, предпочтительнее. Это можно сделать с помощью материализованных столбцов, как показано ниже или в выборке материализованного представления:
Пользователям, вероятно, захочется, чтобы словарь для обогащения ip обновлялся периодически на основе новых данных. Это можно сделать с помощью оговорки LIFETIME словаря, которая вызовет периодическую перезагрузку словаря из базовой таблицы. Чтобы обновить базовую таблицу, смотрите "Обновляемые материализованные представления".
Вышеупомянутые страны и координаты предлагают возможности визуализации, помимо группировки и фильтрации по странам. Для вдохновения смотрите "Визуализация геоданных".
Использование регулярных выражений в словарях (анализ строки User-Agent)
Анализ строк user agent является классической задачей регулярных выражений и общим требованием в наборах данных на основе журналов и трасс. ClickHouse обеспечивает эффективный анализ user agent с помощью Словарей деревьев регулярных выражений.
Словари деревьев регулярных выражений определяются в открытом исходном коде ClickHouse с использованием типа источника словаря YAMLRegExpTree, который предоставляет путь к файлу YAML, содержащему дерево регулярных выражений. Если вы хотите предоставить свой собственный словарь регулярных выражений, подробности о необходимой структуре можно найти здесь. Ниже мы сосредотачиваемся на анализе строк user-agent, используя uap-core и загружаем наш словарь для поддерживаемого формата CSV. Этот подход совместим с OSS и ClickHouse Cloud.
Создайте следующие таблицы памяти. Эти таблицы содержат наши регулярные выражения для анализа устройств, браузеров и операционных систем.
Эти таблицы можно заполнить из следующих общедоступных CSV-файлов, используя табличную функцию url:
С нашими заполненными таблицами памяти, мы можем загружать наши словари регулярных выражений. Обратите внимание, что нам нужно указать ключевые значения как столбцы - это будут атрибуты, которые мы можем извлечь из user agent.
С загруженными словарями мы можем предоставить пример user-agent и протестировать наши новые возможности извлечения словаря:
Учитывая правила, касающиеся строк user agents, они редко изменяются, и словарь нуждается в обновлении только в ответ на новые браузеры, операционные системы и устройства, поэтому имеет смысл выполнять это извлечение во время вставки.
Мы можем выполнить эту работу, используя материализованный столбец или используя материализованное представление. Ниже мы модифицируем материализованное представление, использованное ранее:
Это требует от нас изменить схему для целевой таблицы otel_logs_v2:
После перезапуска сборщика и вставки структурированных логов, основанных на ранее задокументированных шагах, мы можем запрашивать наши новые извлеченные столбцы Device, Browser и Os.
Обратите внимание на использование кортежей для этих столбцов user agent. Кортежи рекомендуются для сложных структур, где иерархия известна заранее. Подколонки предлагают такую же производительность как обычные столбцы (в отличие от ключей Map), позволяя использовать разнородные типы.
Дальнейшее чтение
Для получения дополнительных примеров и деталей по словарям мы рекомендуем следующие статьи:
Ускорение запросов
ClickHouse поддерживает ряд техник для ускорения производительности запросов. Следующие действия следует рассматривать только после выбора подходящего первичного/упорядочивающего ключа для оптимизации наиболее популярных паттернов доступа и максимизации сжатия. Это обычно окажет наибольшее влияние на производительность с наименьшими затратами.
Мы можем представить, что это может быть распространенный линейный график, который пользователи строят с помощью Grafana. Этот запрос, безусловно, очень быстрый - набор данных содержит только 10 миллионов строк, и ClickHouse работает быстро! Однако, если мы увеличим объем данных до миллиардов и триллионов строк, мы хотели бы поддерживать такую производительность запросов.
Этот запрос будет в 10 раз быстрее, если мы используем таблицу otel_logs_v2, которая является результатом нашего предыдущего материализованного представления, которое извлекает ключ размера из карты LogAttributes. Мы используем сырые данные здесь только в иллюстративных целях и рекомендуем использовать предыдущее представление, если это распространенный запрос.
Нам нужна таблица для получения результатов, если мы хотим вычислить это во время вставки, используя материализованное представление. Эта таблица должна хранить только 1 строку на час. Если обновление получено для уже существующего часа, другие столбцы должны быть объединены в строку существующего часа. Для того чтобы произошло это слияние инкрементальных состояний, частичные состояния должны храниться для других столбцов.
Это требует специального типа движка в ClickHouse: SummingMergeTree. Он заменяет все строки с одинаковым ключом сортировки одной строкой, которая содержит суммированные значения для числовых столбцов. Следующая таблица будет объединять любые строки с одинаковой датой, суммируя любые числовые столбцы.
Чтобы продемонстрировать наше материализованное представление, предположим, что наша таблица bytes_per_hour пуста и еще не получила никаких данных. Наше материализованное представление выполняет вышеуказанный SELECT на данных, вставленных в otel_logs (это будет выполняться по блокам заданного размера), с результатами, отправляемыми в bytes_per_hour. Синтаксис приведен ниже:
Клавиша TO здесь является ключевой, указывая, куда будут отправлены результаты, то есть в bytes_per_hour.
Если мы перезапустим наш OTel Collector и повторно отправим логи, таблица bytes_per_hour будет инкрементально заполняться вышеуказанным результатом запроса. После завершения мы можем подтвердить размер нашей таблицы bytes_per_hour - у нас должно быть 1 строка на час:
Мы фактически уменьшили количество строк здесь с 10 миллионов (в otel_logs) до 113, сохранив результат нашего запроса. Ключевым моментом здесь является то, что если новые логи вставляются в таблицу otel_logs, новые значения будут отправлены в bytes_per_hour для их соответствующего часа, где они будут автоматически объединены асинхронно в фоновом режиме - сохраняя только одну строку на час, bytes_per_hour всегда будет как малым, так и актуальным.
Поскольку слияние строк происходит асинхронно, при выполнении запроса может быть более одной строки на час. Чтобы гарантировать, что все ожидающие строки будут объединены во время выполнения запроса, у нас есть два варианта:
- Использовать
FINALмодификатор в имени таблицы (что мы сделали для запроса подсчета выше). - Агрегировать по ключу сортировки, используемому в нашей финальной таблице, то есть по Timestamp и суммировать метрики.
Обычно второй вариант более эффективен и гибок (таблица может использоваться для других целей), но первый может быть проще для некоторых запросов. Мы показываем оба варианта ниже:
Это ускорило наш запрос с 0.6с до 0.008с - более чем в 75 раз!
Эти экономии могут быть еще больше при работе с более крупными наборами данных с более сложными запросами. См. здесь для примеров.
Более сложный пример
В приведенном выше примере агрегируется простое количество за час, используя SummingMergeTree. Статистика, выходящая за пределы простых сумм, требует другого движка целевой таблицы: AggregatingMergeTree.
Предположим, мы хотим вычислить количество уникальных IP-адресов (или уникальных пользователей) за день. Запрос для этого:
Чтобы сохранить подсчет кардинальности для инкрементального обновления, требуется AggregatingMergeTree.
Чтобы убедиться, что ClickHouse знает, что агрегатные состояния будут храниться, мы определяем столбец UniqueUsers как тип AggregateFunction, указывая источник функции для частичных состояний (uniq) и тип исходного столбца (IPv4). Как и в случае с SummingMergeTree, строки с одинаковым значением ключа ORDER BY будут объединены (Hour в приведенном выше примере).
Связанное материализованное представление использует предыдущий запрос:
Обратите внимание, как мы добавляем суффикс State в конец наших агрегатных функций. Это гарантирует, что возвращается агрегатное состояние функции, а не окончательный результат. Это состояние будет содержать дополнительную информацию, позволяющую этому частичному состоянию объединиться с другими состояниями.
После того как данные будут загружены повторно, через перезапуск коллекторов, мы можем подтвердить, что в таблице unique_visitors_per_hour доступно 113 строк.
Наш окончательный запрос должен использовать суффикс Merge для наших функций (поскольку в столбцах хранятся частичные состояния агрегации):
Обратите внимание, что мы используем GROUP BY здесь вместо использования FINAL.
Использование материализованных представлений (инкрементальные) для быстрых запросов
Пользователи должны учитывать свои шаблоны доступа при выборе ключа сортировки ClickHouse с колонками, которые часто используются в фильтрах и агрегационных клаузах. Это может быть ограничивающим моментом в случаях наблюдаемости, когда у пользователей более разнообразные шаблоны доступа, которые нельзя охватить в одном наборе колонок. Это лучше иллюстрируется на примере, встроенном в стандартные схемы OTel. Рассмотрим стандартную схему для трасс:
Эта схема оптимизирована для фильтрации по ServiceName, SpanName и Timestamp. В трассировке пользователям также нужна возможность выполнять запросы по определенному TraceId и получать ассоциированные span трассы. Хотя это присутствует в ключе сортировки, его расположение в конце означает, что фильтрация не будет такой эффективной и вероятно, что значительное количество данных потребуется просканировать при получении одной трассы.
OTel Collector также устанавливает материализованное представление и связанную таблицу для решения этой проблемы. Таблица и представление приведены ниже:
Это представление эффективно гарантирует, что таблица otel_traces_trace_id_ts имеет минимальные и максимальные временные метки для трассы. Эта таблица, отсортированная по TraceId, позволяет эффективно извлекать эти временные метки. Эти диапазоны временных меток могут, в свою очередь, использоваться при запросе главной таблицы otel_traces. Более конкретно, когда Grafana извлекает трассу по ее идентификатору, она использует следующий запрос:
CTE здесь определяет минимальную и максимальную временную метку для идентификатора трассы ae9226c78d1d360601e6383928e4d22d, прежде чем использовать это для фильтрации главной таблицы otel_traces для её ассоциированных span.
Этот же подход можно применить к аналогичным шаблонам доступа. Мы исследуем аналогичный пример в моделировании данных здесь.
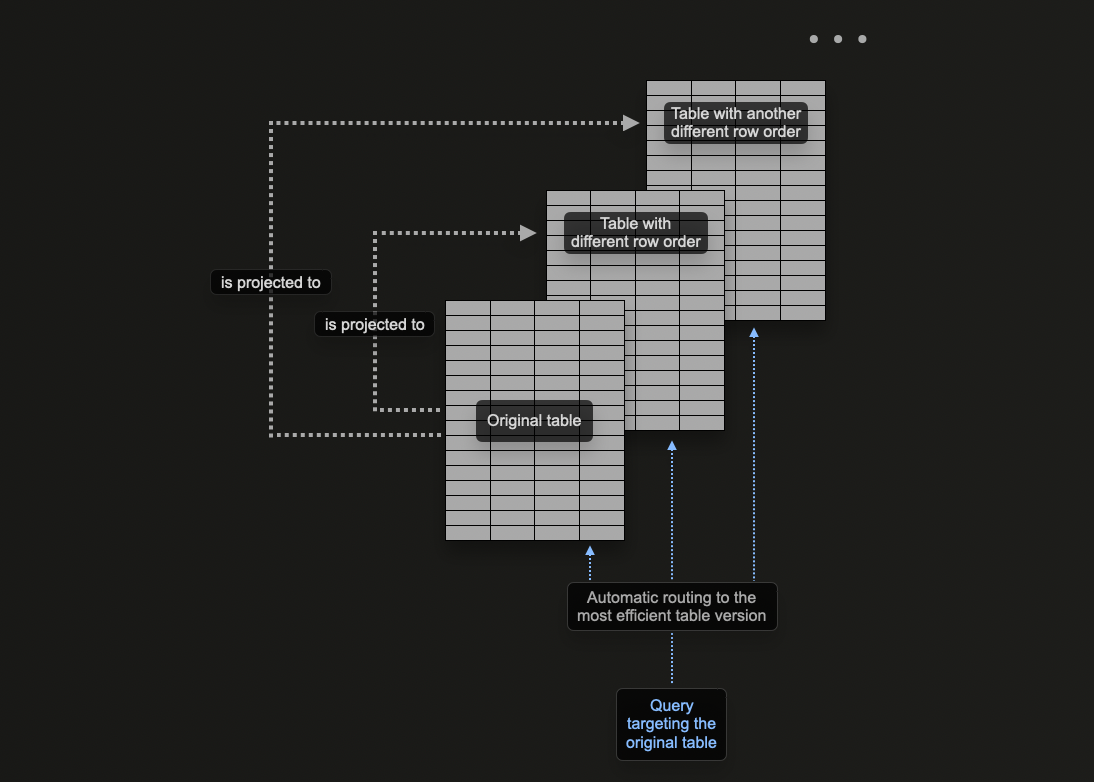
Использование проекций
Проекции ClickHouse позволяют пользователям указывать несколько клауз за сортировку для таблицы.
В предыдущих разделах мы исследовали, как материализованные представления могут использоваться в ClickHouse для предварительного вычисления агрегаций, трансформации строк и оптимизации запросов на наблюдаемость для различных шаблонов доступа.
Мы привели пример, где материализованное представление отправляет строки в целевую таблицу с другим ключом сортировки, чем оригинальная таблица, получающая вставки в целях оптимизации запросов по идентификатору трассы.
Проекции можно использовать для решения той же проблемы, позволяя пользователю оптимизировать запросы по колонке, не входящей в первичный ключ.
В теории, эта возможность может быть использована для предоставления нескольких ключей сортировки для таблицы, с одним весом недостатком: дублированием данных. В частности, данные необходимо будет записывать в порядке основного первичного ключа, помимо порядка, указанного для каждой проекции. Это замедлит вставки и потребует больше дискового пространства.
Проекции предлагают многие из тех же возможностей, что и материализованные представления, но должны использоваться с осторожностью, и последние часто предпочтительнее. Пользователям следует понимать недостатки и когда их применять. Например, хотя проекции можно использовать для предварительного вычисления агрегаций, мы рекомендуем пользователям использовать материализованные представления для этого.
Рассмотрим следующий запрос, который фильтрует нашу таблицу otel_logs_v2 по коду ошибки 500. Это вероятно распространенный шаблон доступа для логирования, когда пользователи хотят фильтровать по кодам ошибок:
Мы не выводим результаты здесь, используя FORMAT Null. Это заставляет все результаты считываться, но не возвращаться, предотвращая таким образом раннее завершение запроса из-за LIMIT. Это делается только для того, чтобы показать время, потраченное на сканирование всех 10 миллионов строк.
Указанный выше запрос требует линейного сканирования с выбранным ключом сортировки (ServiceName, Timestamp). Хотя мы могли бы добавить Status в конец ключа сортировки, улучшив производительность для указанного выше запроса, мы также можем добавить проекцию.
Обратите внимание, что сначала необходимо создать проекцию, а затем материализовать ее. Эта последняя команда приводит к тому, что данные хранятся дважды на диске в двух различных порядках. Проекцию также можно определить при создании данных, как показано ниже, и она будет автоматически поддерживаться по мере вставки данных.
Важно отметить, что если проекция создается через ALTER, её создание происходит асинхронно, когда выполняется команда MATERIALIZE PROJECTION. Пользователи могут подтвердить ход выполнения этой операции с помощью следующего запроса, дожидаясь is_done=1.
Если мы повторим вышеуказанный запрос, мы увидим, что производительность значительно улучшилась за счет дополнительного хранилища (см. "Измерение размера таблицы и сжатия" для измерения этого).
В приведенном выше примере мы указываем столбцы, использованные в предыдущем запросе, в проекции. Это означает, что только указанные столбцы будут храниться на диске в рамках проекции, отсортированные по Status. Если бы, с другой стороны, мы использовали SELECT * здесь, все столбцы были бы сохранены. Хотя это позволило бы большему количеству запросов (с использованием любой подмножества столбцов) выиграть от проекции, потребуется больше места для хранения. Для измерения дискового пространства и сжатия см. "Измерение размера таблицы и сжатия".
Вторичные/Индексы для пропуска данных
Независимо от того, насколько хорошо настроен первичный ключ в ClickHouse, некоторые запросы неизбежно потребуют полного сканирования таблицы. Хотя это можно смягчить с помощью материализованных представлений (и проекций для некоторых запросов), их использование требует дополнительного обслуживания, и пользователи должны быть осведомлены об их наличии, чтобы гарантировать их использование. В то время как традиционные реляционные базы данных решают эту проблему с помощью вторичных индексов, они неэффективны в колонно-ориентированных базах данных, таких как ClickHouse. Вместо этого ClickHouse использует индексы "пропуска", которые могут значительно улучшить производительность запросов, позволяя базе данных пропускать большие объемы данных, не содержащие совпадающих значений.
Стандартные схемы OTel используют вторичные индексы, пытаясь ускорить доступ к картам. Хотя мы находим их в целом неэффективными и не рекомендуем копировать их в вашу пользовательскую схему, индексы пропуска все же могут быть полезны.
Пользователям следует прочитать и понять руководство по вторичным индексам перед тем, как пытаться их применять.
В общем, они эффективны, когда существует сильная корреляция между первичным ключом и целевым, не первичным столбцом/выражением, и пользователи ищут редкие значения, то есть те, которые не встречаются во многих гранулах.
Фильтры Блума для текстового поиска
Для запросов по наблюдаемости вторичные индексы могут быть полезны, когда пользователям необходимо выполнять текстовый поиск. В частности, индексы фильтров Блума на основе ngram и токенов ngrambf_v1 и tokenbf_v1 могут использоваться для ускорения поиска по строковым столбцам с операторами LIKE, IN и hasToken. Важно отметить, что индекс на основе токенов генерирует токены, используя неалфавитные символы в качестве разделителя. Это означает, что только токены (или целые слова) могут быть сопоставлены во время выполнения запроса. Для более детального сопоставления можно использовать N-gram фильтр Блума. Он разбивает строки на n-grams заданного размера, позволяя тем самым выполнить сопоставление подслов.
Чтобы оценить токены, которые будут сгенерированы и, следовательно, сопоставлены, можно использовать функцию tokens:
Функция ngram предоставляет аналогичные возможности, где размер ngram может быть указан в качестве второго параметра:
ClickHouse также имеет экспериментальную поддержку обратных индексов в качестве вторичного индекса. В настоящее время мы не рекомендуем их для наборов данных журналов, но ожидаем, что они заменят фильтры Блума на основе токенов, когда они будут готовы к производству.
Для целей этого примера мы используем набор данных структурированных журналов. Предположим, мы хотим подсчитать журналы, в которых столбец Referer содержит ultra.
Здесь нам нужно сопоставить размером ngram равным 3. Поэтому мы создаем индекс ngrambf_v1.
Индекс ngrambf_v1(3, 10000, 3, 7) здесь принимает четыре параметра. Последний из них (значение 7) представляет собой семя. Остальные представляют размер ngram (3), значение m (размер фильтра) и количество хеш-функций k (7). Значения k и m требуют настройки и будут зависеть от количества уникальных ngrams/токенов и вероятности того, что фильтр даст ложноположительный результат, таким образом подтверждая, что значение отсутствует в грануле. Мы рекомендуем эти функции для определения этих значений.
Если настроить их правильно, ускорение может быть значительным:
Вышеуказанное предназначено только для иллюстрации. Мы рекомендуем пользователям извлекать структуру из своих журналов при вставке, а не пытаться оптимизировать текстовые поиски с использованием токенизированных фильтров Блума. Однако есть случаи, когда у пользователей есть трассировки стека или другие большие строки, для которых текстовый поиск может быть полезен из-за менее детерминированной структуры.
Некоторые общие рекомендации по использованию фильтров Блума:
Цель фильтра Блума - отфильтровать гранулы, избегая необходимости загружать все значения для столбца и выполнять линейный поиск. Клауза EXPLAIN с параметром indexes=1 может быть использована для определения количества гранул, которые были пропущены. Рассмотрите ответы ниже для оригинальной таблицы otel_logs_v2 и таблицы otel_logs_bloom с фильтром Блума ngram.
Фильтр Блума обычно будет быстрее, если он меньше самого столбца. Если он больше, то, вероятно, преимущества в производительности будут незначительными. Сравните размер фильтра со столбцом с помощью следующих запросов:
В приведенных выше примерах мы видим, что вторичный индекс фильтра Блума имеет размер 12 МБ - почти в 5 раз меньше сжатого размера самого столбца, который составляет 56 МБ.
Фильтры Блума могут требовать значительной настройки. Мы рекомендуем следовать примечаниям здесь, которые могут быть полезны для определения оптимальных настроек. Фильтры Блума также могут быть дорогостоящими во время вставки и слияния. Пользователи должны оценить влияние на производительность вставки перед добавлением фильтров Блума в производственные среды.
Дальнейшие сведения о вторичных индексах для пропуска можно найти здесь.
Извлечение из карт
Тип Map широко используется в схемах OTel. Этот тип требует, чтобы значения и ключи имели один и тот же тип - что достаточно для метаданных, таких как метки Kubernetes. Имейте в виду, что при запросе подконечного ключа типа Map загружается весь родительский столбец. Если у карты много ключей, это может привести к значительным затратам на запрос, поскольку нужно прочитать больше данных с диска, чем если бы ключ существовал как столбец.
Если вы часто запрашиваете определенный ключ, рассмотрите возможность перемещения его в собственный выделенный столбец на корневом уровне. Это обычно задача, выполняемая в ответ на распространенные шаблоны доступа и после развертывания, и может быть трудна для предсказания до начала работы в производственной среде. См. "Управление изменениями схемы" о том, как изменить вашу схему после развертывания.
Измерение размера таблицы и сжатия
Одной из основных причин использования ClickHouse для наблюдаемости является сжатие.
Помимо значительного снижения затрат на хранение, меньше данных на диске означает меньше ввода-вывода и более быстрые запросы и вставки. Снижение ввода-вывода превысит накладные расходы любого алгоритма сжатия с точки зрения CPU. Таким образом, улучшение сжатия данных должно быть первым приоритетом, когда речь идет о том, чтобы обеспечить быструю работу запросов в ClickHouse.
Подробности об измерении сжатия можно найти здесь.