Проектирование схем
Это Часть 2 руководства по миграции с PostgreSQL на ClickHouse. Этот материал можно считать вводным, с целью помочь пользователям развернуть первоначальную функциональную систему, соответствующую лучшим практикам ClickHouse. Избегается сложные темы и это не приведет к полностью оптимизированной схеме; скорее, это предоставит надежную основу для пользователей, чтобы построить производственную систему и на базе этого учиться.
Набор данных Stack Overflow содержит ряд связанных таблиц. Мы рекомендуем сосредоточить миграцию на первичной таблице в первую очередь. Это может быть не обязательно самая большая таблица, а та, по которой вы ожидаете получить наибольшее количество аналитических запросов. Это позволит вам ознакомиться с основными концепциями ClickHouse, которые особенно важны, если вы пришли из преимущественно OLTP-среды. Эта таблица может потребовать переработки по мере добавления дополнительных таблиц, чтобы полностью использовать функции ClickHouse и достичь оптимальной производительности. Мы изучаем этот процесс моделирования в нашей Документации по моделированию данных.
Установление первоначальной схемы
Соблюдая этот принцип, мы сосредоточимся на основной таблице posts. Схема Postgres для этой таблицы показана ниже:
Чтобы установить эквивалентные типы для каждого из приведенных выше столбцов, мы можем использовать команду DESCRIBE с табличной функцией Postgres. Измените следующую команду для вашей инстанции Postgres:
Это дает нам первоначальную не оптимизированную схему.
Без ограничения
NOT NULLстолбцы Postgres могут содержать Null значения. Без проверки значений строк ClickHouse сопоставляет их эквивалентным Nullable типам. Обратите внимание, что первичный ключ не может быть Null, что является обязательным в Postgres.
Мы можем создать таблицу ClickHouse, используя эти типы, с помощью простой команды CREATE AS EMPTY SELECT.
Тот же подход можно использовать для загрузки данных из s3 в других форматах. См. здесь аналогичный пример загрузки этих данных из формата Parquet.
Первоначальная загрузка
Создав таблицу, мы можем вставить строки из Postgres в ClickHouse, используя табличную функцию Postgres.
Эта операция может создавать значительную нагрузку на Postgres. Пользователи могут захотеть восполнить данные альтернативными операциями, чтобы избежать воздействия на производственные нагрузки, например, экспортировать SQL-скрипт. Производительность этой операции будет зависеть от размеров кластера Postgres и ClickHouse и их сетевого соединения.
Каждый
SELECTиз ClickHouse в Postgres использует одно соединение. Это соединение берется из пула подключений на стороне сервера, размеры которого определяются настройкойpostgresql_connection_pool_size(по умолчанию 16).
Если использовать полный набор данных, пример должен загрузить 59 миллионов постов. Подтвердите с помощью простого подсчета в ClickHouse:
Оптимизация типов
Шаги по оптимизации типов для этой схемы идентичны тем, что используются, если данные были загружены из других источников, например, Parquet на S3. Применение процесса, описанного в этом альтернативном руководстве с использованием Parquet, приводит к следующей схеме:
Мы можем заполнить это простым запросом INSERT INTO SELECT, читая данные из нашей предыдущей таблицы и вставляя в эту:
Мы не сохраняем никаких null в нашей новой схеме. Вышеупомянутая вставка неявно преобразует их в значения по умолчанию для их соответствующих типов - 0 для целых чисел и пустое значение для строк. ClickHouse также автоматически преобразует любые числовые значения к их целевой точности.
Первичные (упорядочивающие) ключи в ClickHouse
Пользователи, пришедшие из OLTP баз данных, часто ищут эквивалентную концепцию в ClickHouse. Замечая, что ClickHouse поддерживает синтаксис PRIMARY KEY, пользователи могут быть искушены определить схему своей таблицы, используя те же ключи, что и в исходной OLTP базе данных. Это нецелесообразно.
Чем первичные ключи ClickHouse отличаются?
Чтобы понять, почему использование вашего OLTP первичного ключа в ClickHouse нецелесообразно, пользователи должны понимать основы индексирования ClickHouse. Мы используем Postgres как пример для сравнения, но эти общие концепции применимы и к другим OLTP базам данных.
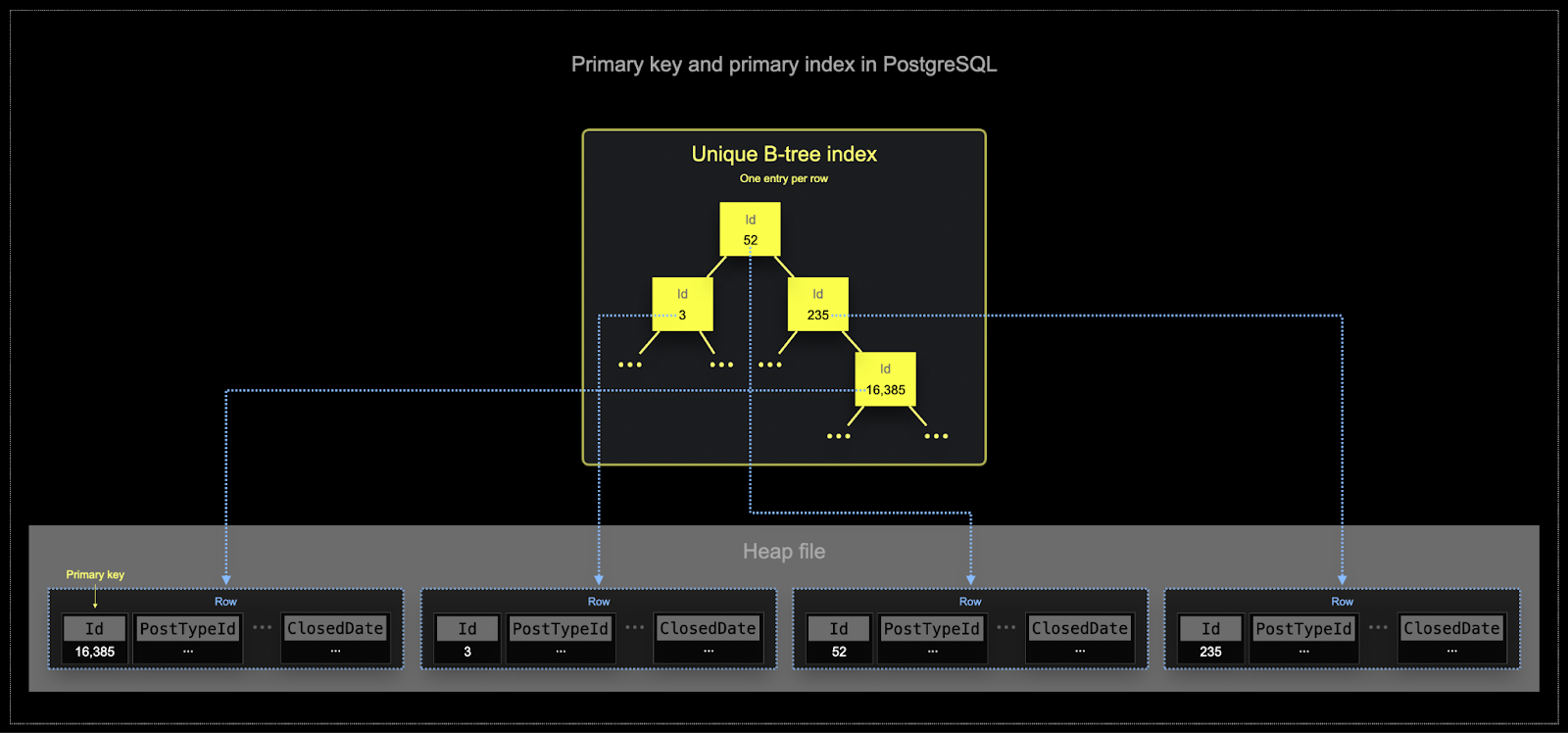
- Первичные ключи Postgres, по определению, уникальны для каждой строки. Использование структур B-дерева позволяет эффективно находить отдельные строки по этому ключу. Хотя ClickHouse может быть оптимизирован для поиска значения одной строки, аналитические нагрузки обычно требуют чтения нескольких столбцов, но для множества строк. Фильтры часто должны определять подмножество строк, на которых будет выполняться агрегация.
- Эффективность памяти и диска имеет первостепенное значение в масштабе, на котором ClickHouse часто используется. Данные записываются в таблицы ClickHouse партиями, известными как части, с применением правил для слияния частей в фоновом режиме. В ClickHouse каждая часть имеет свой первичный индекс. Когда части сливаются, первичные индексы слитых частей также сливаются. В отличие от Postgres, эти индексы не строятся для каждой строки. Вместо этого первичный индекс для части имеет одну запись индекса на группу строк - эта техника называется разреженным индексированием.
- Разреженное индексирование возможно, потому что ClickHouse хранит строки для части на диске в порядке, заданном указанным ключом. Вместо того, чтобы напрямую находить отдельные строки (как в индексе на основе B-дерева), разреженный первичный индекс позволяет быстро (через бинарный поиск по записям индекса) определить группы строк, которые могут соответствовать запросу. Найденные группы потенциально соответствующих строк затем параллельно передаются в движок ClickHouse, чтобы найти соответствия. Этот дизайн индекса позволяет сделать первичный индекс небольшим (он полностью помещается в основную память), при этом значительно ускоряя время выполнения запросов, особенно для диапазонных запросов, которые типичны для аналитических задач. Для получения более подробной информации мы рекомендуем это углубленное руководство.
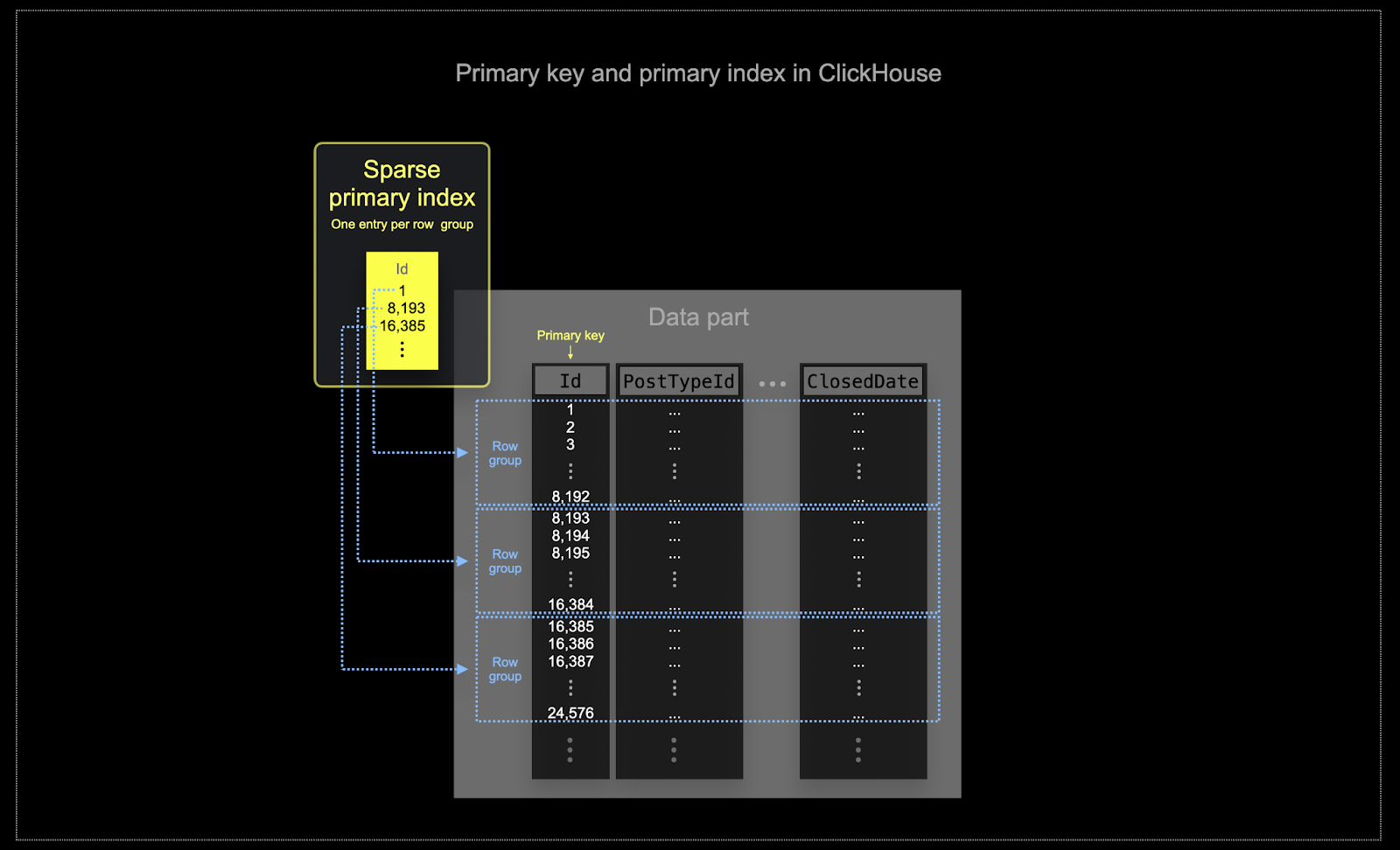
Выбранный ключ в ClickHouse определяет не только индекс, но и порядок, в котором данные записываются на диск. Из-за этого это может значительно повлиять на уровни сжатия, что, в свою очередь, может повлиять на производительность запросов. Упорядочивающий ключ, который заставляет значения большинства столбцов записываться в непрерывном порядке, позволяет выбранному алгоритму сжатия (и кодекам) более эффективно сжимать данные.
Все столбцы в таблице будут отсортированы на основе значения указанного упорядочивающего ключа, независимо от того, включены ли они в сам ключ. Например, если
CreationDateиспользуется как ключ, порядок значений во всех других столбцах будет соответствовать порядку значений в столбцеCreationDate. Можно указать несколько упорядочивающих ключей - это будет упорядочивать с той же семантикой, что и предложениеORDER BYв запросеSELECT.
Выбор упорядочивающего ключа
Для соображений и шагов по выбору упорядочивающего ключа, используя таблицу постов в качестве примера, см. здесь.
Сжатие
Столбцовая структура хранения ClickHouse означает, что сжатие часто будет значительно лучше по сравнению с Postgres. Следующее иллюстрирует сравнение требований к хранению для всех таблиц Stack Overflow в обеих базах данных:
Дополнительные детали по оптимизации и измерению сжатия можно найти здесь.