Загрузка данных из PostgreSQL в ClickHouse
Это Часть 1 руководства по миграции из PostgreSQL в ClickHouse. Этот контент можно считать вводным, с целью помочь пользователям развернуть первоначальную функциональную систему, соответствующую лучшим практикам ClickHouse. Он избегает сложных тем и не приводит к полностью оптимизированной схеме; скорее, он предоставляет надежную основу для пользователей, чтобы построить производственную систему и углубить свои знания.
Набор данных
В качестве примера набора данных для демонстрации типичной миграции из Postgres в ClickHouse мы используем набор данных Stack Overflow, задокументированный здесь. Этот набор данных содержит все post, vote, user, comment и badge, которые имели место на Stack Overflow с 2008 года по апрель 2024 года. Схема PostgreSQL для этих данных показана ниже:
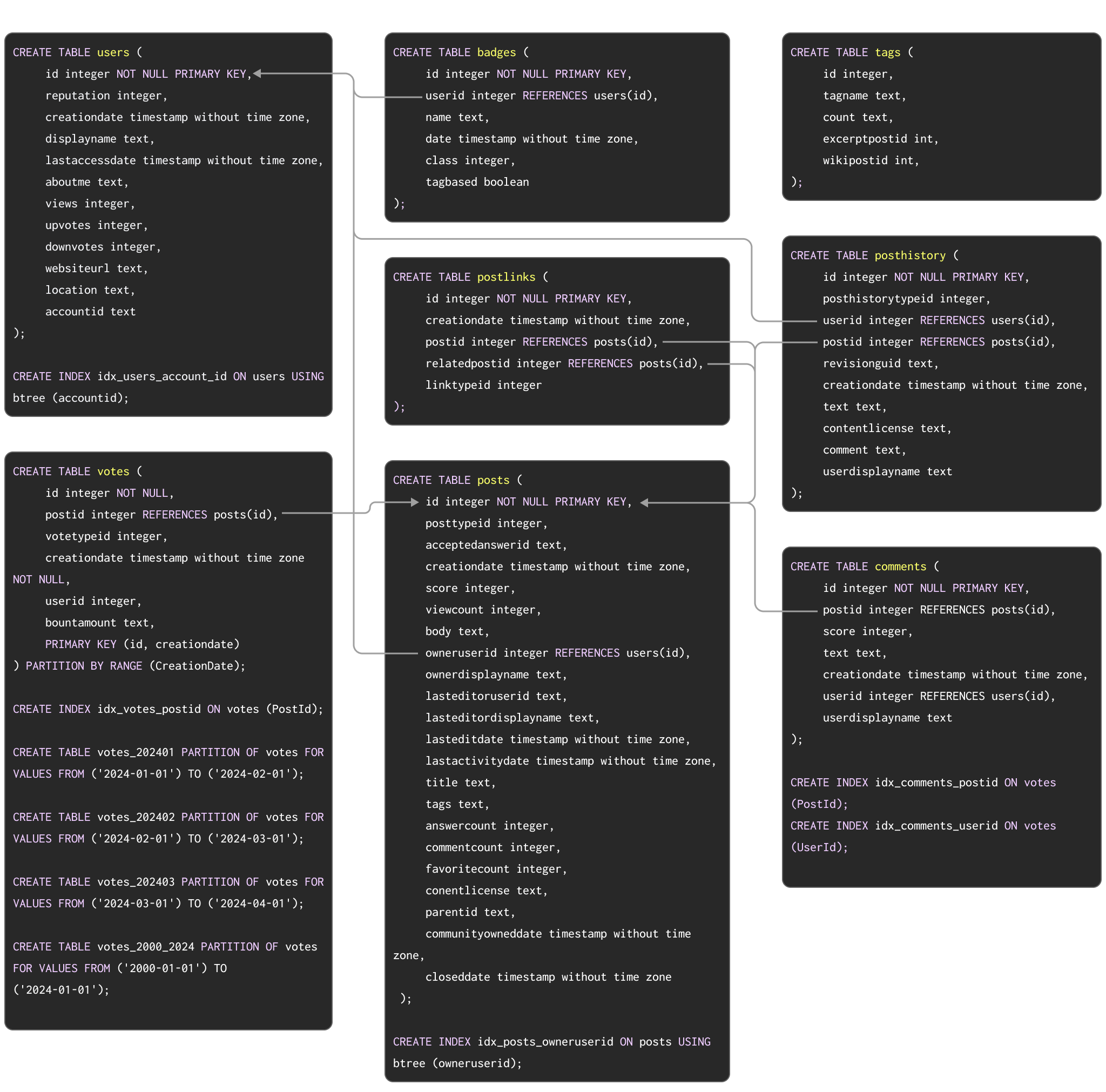
Команды DDL для создания таблиц в PostgreSQL доступны здесь.
Эта схема, хотя и не обязательно самая оптимальная, использует ряд популярных функций PostgreSQL, включая первичные ключи, внешние ключи, партиционирование и индексы.
Мы мигрируем каждую из этих концепций на их эквиваленты в ClickHouse.
Для пользователей, которые хотят заполнить этот набор данных в экземпляре PostgreSQL для тестирования этапов миграции, мы предоставили данные в формате pg_dump для загрузки с DDL, и последующие команды загрузки данных показаны ниже:
Хотя этот набор данных мал для ClickHouse, он значителен для Postgres. В приведенном выше примере представлена подмножество, охватывающее первые три месяца 2024 года.
Хотя наши примеры результатов используют полный набор данных для демонстрации различий в производительности между Postgres и ClickHouse, все шаги, документированные ниже, функционально идентичны с меньшим подмножеством. Пользователи, желающие загрузить полный набор данных в Postgres, могут ознакомиться здесь. Из-за внешних ограничений, наложенных вышеупомянутой схемой, полный набор данных для PostgreSQL содержит только те строки, которые соответствуют ссылочной целостности. Версию Parquet без таких ограничений можно легко загрузить напрямую в ClickHouse при необходимости.
Миграция данных
Миграция данных между ClickHouse и Postgres делится на два основных типа рабочих нагрузок:
- Первичная массовая загрузка с периодическими обновлениями - Необходимость мигрировать первоначальный набор данных вместе с периодическими обновлениями через заданные интервалы, например, ежедневно. Обновления здесь обрабатываются путем повторной отправки изменившихся строк - идентифицируемых либо по столбцу, который можно использовать для сравнения (например, по дате), либо по значению
XMIN. Удаления обрабатываются с полным периодическим перезагрузкой набора данных. - Репликация в реальном времени или CDC - Необходимость мигрировать первоначальный набор данных. Изменения в этом наборе данных должны отражаться в ClickHouse почти в реальном времени с задержкой всего несколько секунд. Это фактически процесс захвата изменений данных (CDC), при котором таблицы в Postgres должны быть синхронизированы с ClickHouse, то есть вставки, обновления и удаления в таблице Postgres должны применяться к эквивалентной таблице в ClickHouse.
Первичная массовая загрузка с периодическими обновлениями
Эта рабочая нагрузка представляет собой более простую из вышеуказанных нагрузок, поскольку изменения могут применяться периодически. Первоначальная массовая загрузка набора данных может быть достигнута с помощью:
- Табличные функции - Используя табличную функцию Postgres в ClickHouse для
SELECTданных из Postgres иINSERTих в таблицу ClickHouse. Это актуально для массовых загрузок до наборов данных в несколько сотен гигабайт. - Экспорты - Экспортируя в промежуточные форматы, такие как CSV или SQL-скрипты. Эти файлы затем могут быть загружены в ClickHouse либо клиентом через оператор
INSERT FROM INFILE, либо с использованием объектного хранилища и их связанных функций, т.е. s3, gcs.
Инкрементальные загрузки, в свою очередь, могут быть расписаны. Если таблица Postgres только получает вставки, и существует инкрементный идентификатор или временная метка, пользователи могут использовать вышеупомянутый подход с таблицами для загрузки инкрементов, т.е. оператор WHERE может быть применен к SELECT. Этот подход также может быть использован для поддержки обновлений, если они гарантированно обновляют тот же столбец. Однако поддержка удалений потребует полной перезагрузки, что может быть трудно осуществить по мере роста таблицы.
Мы демонстрируем первоначальную загрузку и инкрементальную загрузку, используя CreationDate (предполагаем, что он обновляется при изменении строк).
ClickHouse будет пропускать простые операторы
WHERE, такие как=,!=,>,>=,<,<=и IN, на сервер PostgreSQL. Таким образом, инкрементальные загрузки могут быть более эффективными, если существует индекс на столбцах, используемых для определения набора изменений.
Возможный метод определения операций UPDATE при использовании репликации запросов заключается в использовании
XMINсистемного столбца (идентификаторы транзакций) в качестве водяного знака - изменение этого столбца указывает на изменение и, следовательно, может быть применено к целевой таблице. Пользователи, использующие этот подход, должны быть осведомлены о том, что значенияXMINмогут циклически переполняться, и для сравнения требуется полное сканирование таблицы, что делает отслеживание изменений более сложным. Дополнительные сведения об этом подходе см. в разделе "Захват изменений данных (CDC)".
Репликация в реальном времени или CDC
Захват изменений данных (CDC) - это процесс, при котором таблицы синхронизируются между двумя базами данных. Это значительно более сложно, если обновления и удаления должны обрабатываться почти в реальном времени. В настоящее время существует несколько решений:
- PeerDB от ClickHouse - PeerDB предлагает открытое решение для специализированного CDC PostgreSQL, которое пользователи могут выполнять самостоятельно или через SaaS-решение, которое показало хорошую эффективность в масштабе с Postgres и ClickHouse. Решение сосредоточено на низкоуровневых оптимизациях для достижения высокой производительности передачи данных и гарантии надежности между Postgres и ClickHouse. Оно поддерживает как онлайн, так и офлайн загрузки.
PeerDB теперь доступен нативно в ClickHouse Cloud - Сверхбыстрый CDC из Postgres в ClickHouse с нашим новым коннектором ClickPipe - сейчас в публичной бета-версии.
- Постройте свое собственное - Это можно достичь с помощью Debezium + Kafka - Debezium предлагает возможность захвата всех изменений в таблице Postgres, перенаправляя их как события в очередь Kafka. Эти события могут быть затем использованы либо коннектором Kafka ClickHouse, либо ClickPipes в ClickHouse Cloud для вставки в ClickHouse. Это представляет собой Захват изменений данных (CDC), так как Debezium будет не только выполнять первоначальную копию таблиц, но также обеспечивать обнаружение всех последующих обновлений, удалений и вставок в Postgres, что приведет к получению событий на выходе. Это требует тщательной настройки как Postgres, так и Debezium, а также ClickHouse. Примеры можно найти здесь.
Для примеров в этом руководстве мы предполагаем только первоначальную массовую загрузку, сосредоточив внимание на исследовании данных и легкой итерации к производственным схемам, подходящим для других подходов.