Миграция с BigQuery на ClickHouse Cloud
Зачем использовать ClickHouse Cloud вместо BigQuery?
TLDR: Потому что ClickHouse быстрее, дешевле и мощнее, чем BigQuery для современных задач аналитики данных:

Загрузка данных из BigQuery в ClickHouse Cloud
Набор данных
В качестве примера набора данных, чтобы показать типичную миграцию из BigQuery в ClickHouse Cloud, мы используем набор данных Stack Overflow, задокументированный здесь. Он содержит все post, vote, user, comment и badge, которые произошли на Stack Overflow с 2008 по апрель 2024 года. Схема BigQuery для этих данных показана ниже:

Для пользователей, которые хотят загрузить этот набор данных в экземпляр BigQuery для тестирования миграционных шагов, мы предоставили данные для этих таблиц в формате Parquet в GCS bucket, а команды DDL для создания и загрузки таблиц в BigQuery доступны здесь.
Миграция данных
Миграция данных между BigQuery и ClickHouse Cloud делится на два основных типа рабочих нагрузок:
- Начальная массовая загрузка с периодическими обновлениями - Начальный набор данных должен быть мигрирован вместе с периодическими обновлениями через установленные интервалы, например, ежедневно. Обновления здесь обрабатываются повторной отправкой строк, которые изменились, - идентифицированных либо по столбцу, который может быть использован для сравнения (например, дата). Удаления обрабатываются полной периодической перезагрузкой набора данных.
- Реальное время репликации или CDC - Начальный набор данных должен быть мигрирован. Изменения в этом наборе данных должны отражаться в ClickHouse в почти реальном времени с допустимой задержкой в несколько секунд. Это по сути процесс захвата изменений данных (CDC), когда таблицы в BigQuery должны быть синхронизированы с ClickHouse, т.е. вставки, обновления и удаления в таблице BigQuery должны применяться к эквивалентной таблице в ClickHouse.
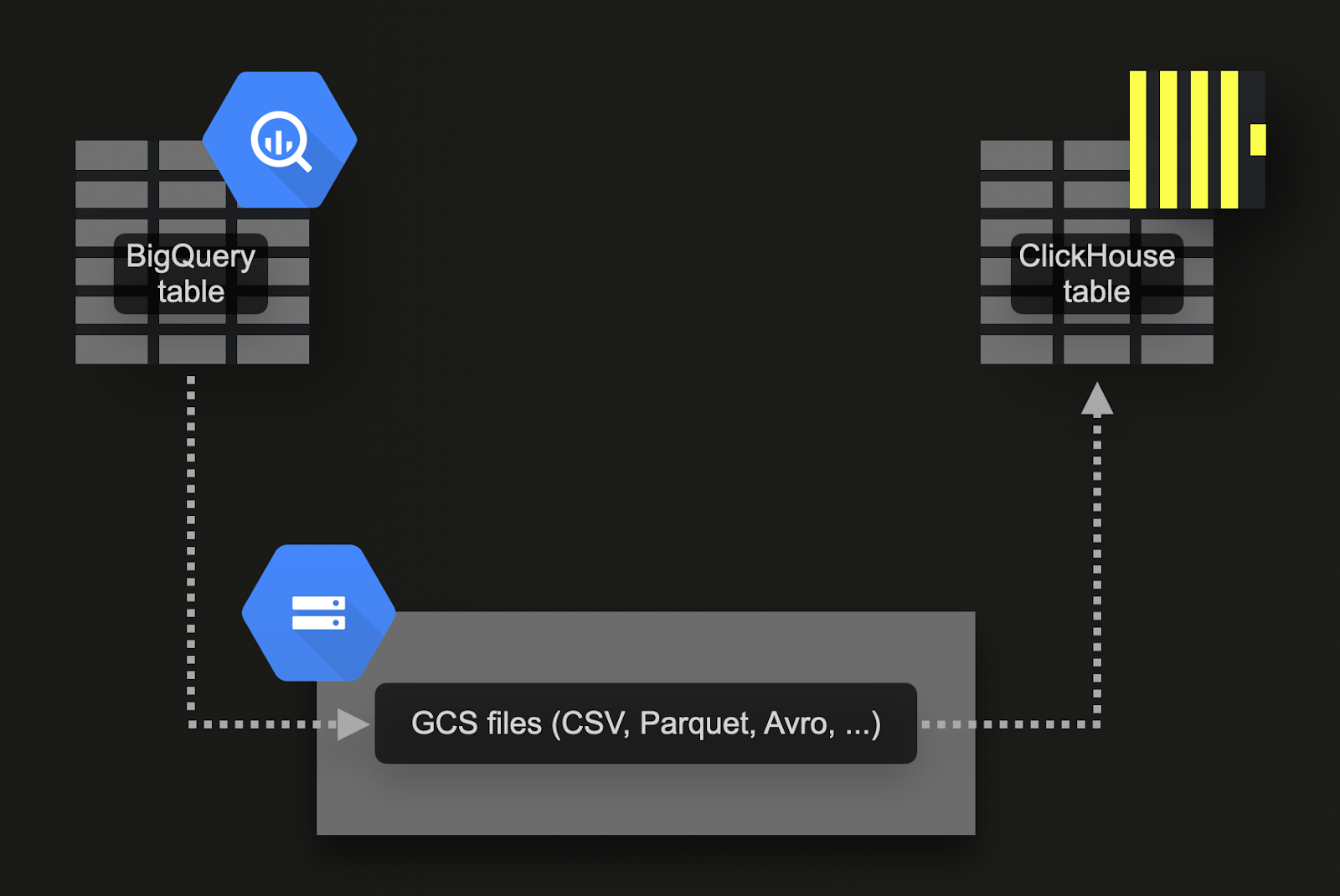
Массовая загрузка через Google Cloud Storage (GCS)
BigQuery поддерживает экспорт данных в объектное хранилище Google (GCS). Для нашего примерного набора данных:
-
Экспортируйте 7 таблиц в GCS. Команды для этого доступны здесь.
-
Импортируйте данные в ClickHouse Cloud. Для этого мы можем использовать табличную функцию gcs. Команды DDL и запросы на импорт доступны здесь. Обратите внимание, что поскольку экземпляр ClickHouse Cloud состоит из нескольких вычислительных узлов, вместо табличной функции
gcsмы используем табличную функцию s3Cluster. Эта функция также работает с gcs bucket и использует все узлы сервиса ClickHouse Cloud для параллельной загрузки данных.
Этот подход имеет ряд преимуществ:
- Функциональность экспорта BigQuery поддерживает фильтрацию для экспорта подмножества данных.
- BigQuery поддерживает экспорт в форматы Parquet, Avro, JSON и CSV и несколько типов сжатия, все из которых поддерживаются ClickHouse.
- GCS поддерживает управление жизненным циклом объектов, что позволяет удалять данные, которые были экспортированы и импортированы в ClickHouse, после заданного периода.
- Google позволяет экспортировать до 50 ТБ в день в GCS бесплатно. Пользователи платят только за хранение в GCS.
- Экспорт автоматически создает несколько файлов, ограничивая каждый максимум до 1 ГБ данных таблицы. Это выгодно для ClickHouse, так как позволяет параллелизировать импорты.
Перед выполнением следующих примеров мы рекомендуем пользователям изучить необходимые разрешения для экспорта и рекомендации по локализации для максимизации производительности экспорта и импорта.
Репликация в реальном времени или CDC через запланированные запросы
Захват изменений данных (CDC) - это процесс, при котором таблицы сохраняются в синхронизации между двумя базами данных. Это значительно сложнее, если обновления и удаления должны обрабатываться в почти реальном времени. Один из подходов - просто планировать периодический экспорт с использованием функциональности запланированных запросов BigQuery. Если вы готовы принять некоторую задержку в вставке данных в ClickHouse, этот подход легко реализуется и поддерживается. Пример приведен в этом блоге.
Проектирование схем
Набор данных Stack Overflow содержит несколько связанных таблиц. Мы рекомендуем сосредоточиться на миграции основной таблицы сначала. Это может быть не обязательно самая большая таблица, но та, по которой вы ожидаете получить наибольшее количество аналитических запросов. Это позволит вам ознакомиться с основными концепциями ClickHouse. Эта таблица может потребовать изменения структуры по мере добавления дополнительных таблиц, чтобы полностью использовать возможности ClickHouse и получить оптимальную производительность. Этот процесс моделирования обсуждается в нашей документации по моделированию данных.
Следуя этому принципу, мы сосредотачиваемся на основной таблице posts. Схема BigQuery для нее показана ниже:
Оптимизация типов
Применение процесса, описанного здесь, приводит к следующей схеме:
Мы можем заполнить эту таблицу с помощью простого INSERT INTO SELECT, читая экспортированные данные из gcs с использованием табличной функции gcs. Обратите внимание, что в ClickHouse Cloud вы также можете использовать совместимую с gcs табличную функцию s3Cluster для параллельной загрузки на нескольких узлах:
Мы не сохраняем пустые значения в нашей новой схеме. Вставка выше неявно преобразует их в значения по умолчанию для соответствующих типов - 0 для целых, и пустое значение для строк. ClickHouse также автоматически преобразует любые числовые данные в их целевую точность.
Чем отличаются первичные ключи ClickHouse?
Как описано здесь, как и в BigQuery, ClickHouse не обеспечивает уникальность значений столбцов первичного ключа таблицы.
Аналогично кластеризации в BigQuery, данные таблицы ClickHouse хранятся на диске, отсортированными по столбцу(ам) первичного ключа. Этот порядок сортировки используется оптимизатором запросов для предотвращения пересортировки, минимизации использования памяти для соединений и включения короткого замыкания для пределов.
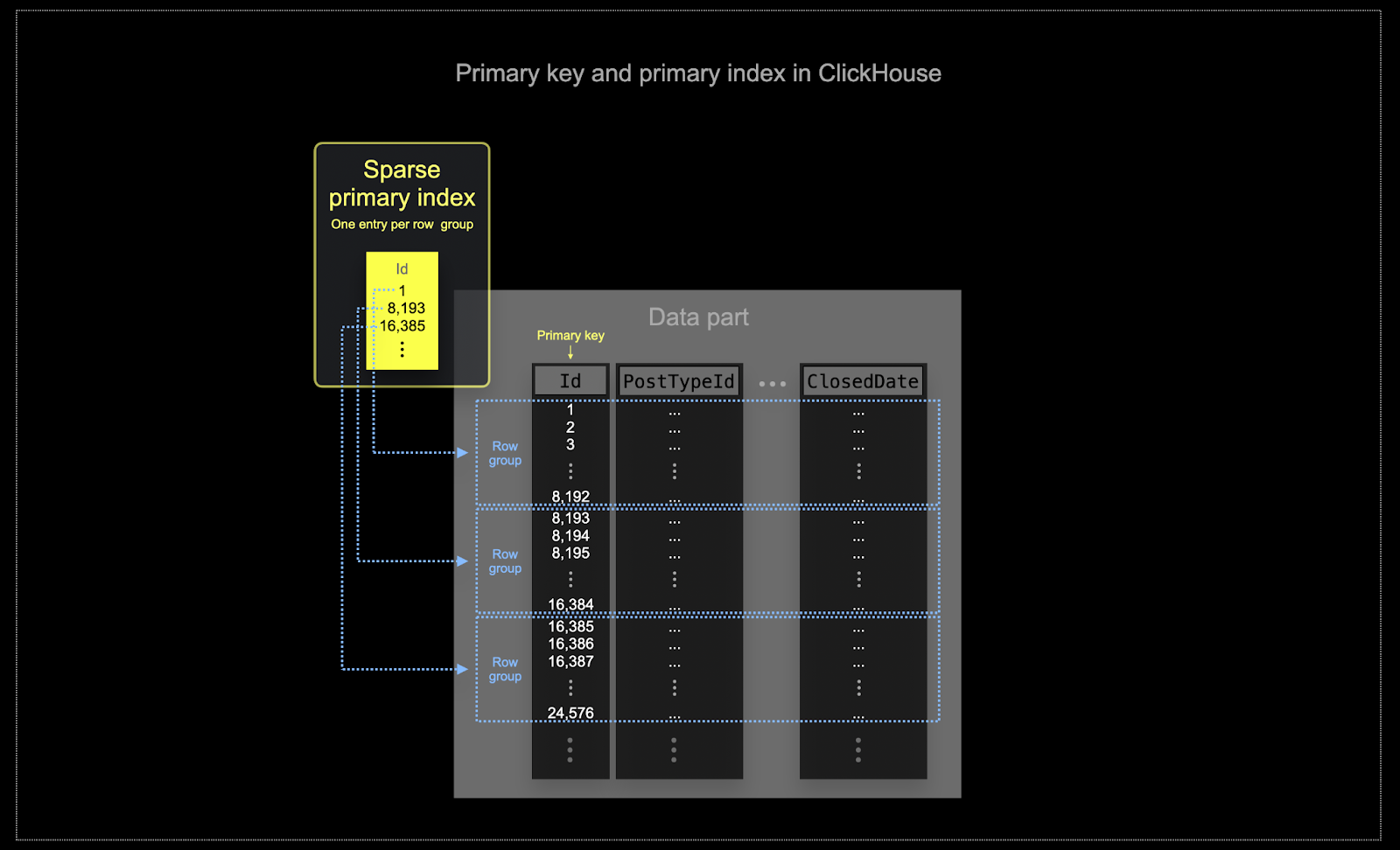
В отличие от BigQuery, ClickHouse автоматически создает разреженный первичный индекс, основанный на значениях столбца первичного ключа. Этот индекс используется для ускорения всех запросов, содержащих фильтры по первичным ключам. В частности:
- Эффективность памяти и использования диска имеет первостепенное значение для масштаба, на котором часто используется ClickHouse. Данные записываются в таблицы ClickHouse большими частями, известными как части, с применением правил объединения частей в фоне. В ClickHouse каждая часть имеет свой первичный индекс. Когда части объединяются, соответственно, объединяются и их первичные индексы. Примечательно, что эти индексы не строятся для каждой строки. Вместо этого первичный индекс для части имеет одну запись на группу строк - эта техника называется разреженным индексированием.
- Разреженное индексирование возможно, потому что ClickHouse хранит строки части на диске в порядке, определённом указанным ключом. Вместо того чтобы прямо находить отдельные строки (как индекс, основанный на B-дереве), разреженный первичный индекс позволяет быстро (через двоичный поиск по записям индекса) идентифицировать группы строк, которые могут потенциально результатировать в совпадении с запросом. Найденные группы потенциально совпадающих строк затем, параллельно, передаются в движок ClickHouse для поиска совпадений. Эта конструкция индекса позволяет сделать первичный индекс компактным (полностью умещающимся в основной памяти), при этом значительно ускоряя выполнение запросов, особенно для диапазонов запросов, типичных для использования в аналитике данных. Для более детальной информации мы рекомендуем это подробное руководство.
Выбранный первичный ключ в ClickHouse определит не только индекс, но и порядок, в котором данные записываются на диск. Из-за этого он может резко повлиять на уровни сжатия, что, в свою очередь, может повлиять на производительность запросов. Порядковый ключ, который заставляет значения большинства столбцов быть записанными в смежном порядке, позволит выбранному алгоритму сжатия (и кодекам) более эффективно сжать данные.
Все данные в таблице будут отсортированы на основе значения заданного порядкового ключа, независимо от того, включены ли они в сам ключ. Например, если
CreationDateиспользуется в качестве ключа, порядок значений во всех остальных столбцах будет соответствовать порядку значений в столбцеCreationDate. Можно указать несколько порядковых ключей - эти ключи упорядочат данные по тем же принципам, что и конструкцияORDER BYв запросеSELECT.
Выбор порядкового ключа
Для рассмотрений и шагов при выборе порядкового ключа, используя таблицу постов в качестве примера, смотрите здесь.
Техники моделирования данных
Мы рекомендуем пользователям, мигрирующим из BigQuery, ознакомиться с руководством по моделированию данных в ClickHouse. В этом руководстве используется тот же набор данных Stack Overflow и изучается множество подходов с использованием функций ClickHouse.
Разделы
Пользователи BigQuery знакомы с концепцией разделения таблиц для повышения производительности и управляемости большими базами данных, разделяя таблицы на более мелкие, более управляемые части, называемые разделами. Такое разделение может быть достигнуто с использованием либо диапазона по определённому столбцу (например, дате), определенных списков или посредством хеша по ключу. Это позволяет администраторам организовать данные на основе конкретных критериев, таких как диапазоны дат или географические расположения.
Разделение помогает улучшить производительность запросов, обеспечивая более быстрый доступ к данным через отсечение разделов и более эффективное индексирование. Оно также упрощает задачи обслуживания, такие как резервное копирование и очистка данных, позволяя выполнять операции на отдельных разделах, а не на всей таблице. Кроме того, разделение может значительно увеличить масштабируемость баз данных BigQuery, распределяя нагрузку по нескольким разделам.
В ClickHouse разделение указывается для таблицы при её первоначальном определении через ключевое слово PARTITION BY. Это ключевое слово может содержать SQL-выражение на любом(ых) столбце(ах), результаты которого определят, в какой раздел будет отправлена строка.
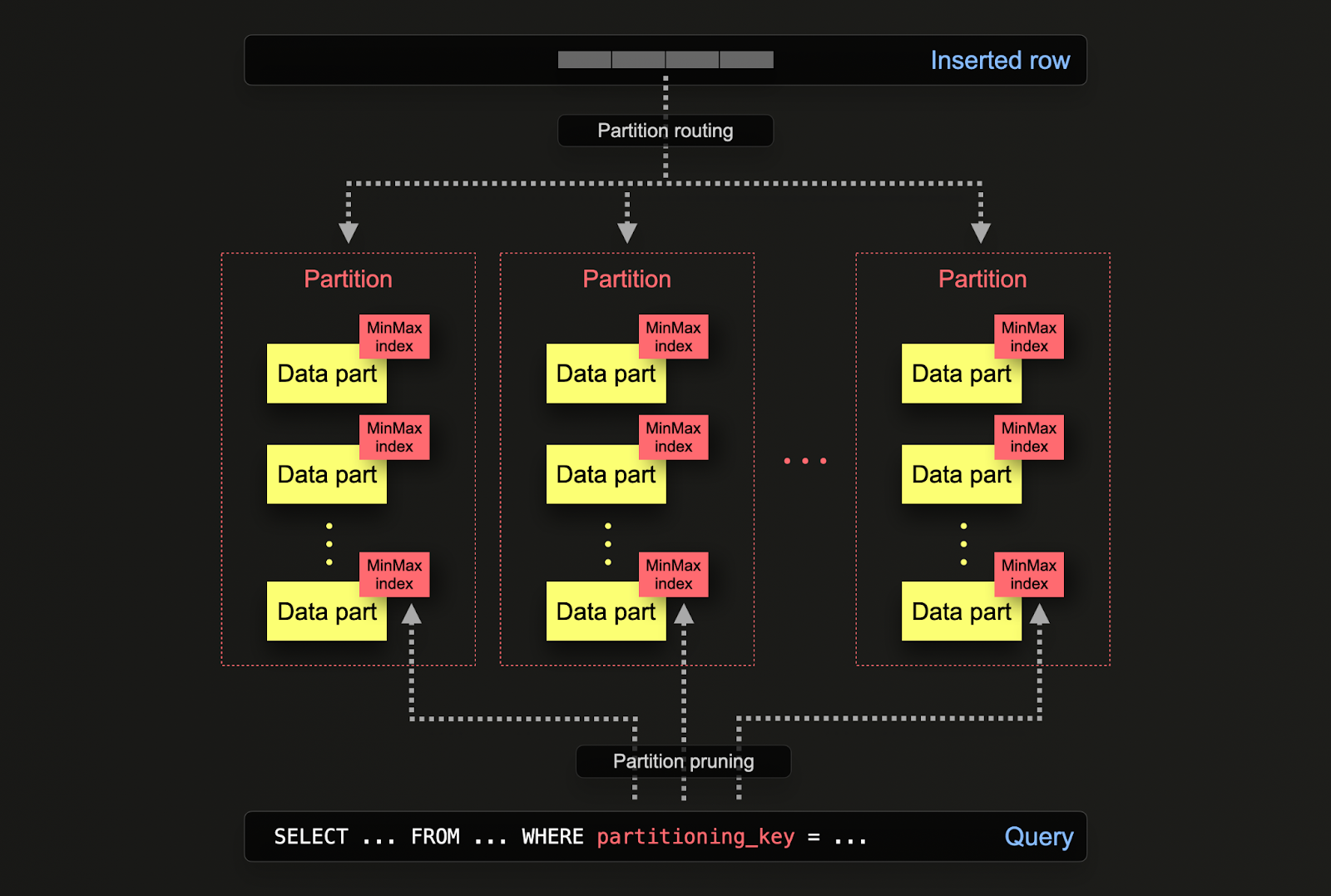
Части данных логически ассоциируются с каждым разделом на диске и могут быть запрошены отдельно. В приведенном ниже примере мы разбиваем таблицу постов по годам, используя выражение toYear(CreationDate). По мере вставки строк в ClickHouse, это выражение будет оцениваться для каждой строки, а строки будут направляться в полученный раздел в форме новых частей данных, принадлежащих этому разделу.
Приложения
Разделение в ClickHouse имеет схожие приложения, как и в BigQuery, но с некоторыми тонкими отличиями. Более конкретно:
- Управление данными - В ClickHouse пользователи должны рассматривать разделение как функцию управления данными, а не как технику оптимизации запросов. Разделяя данные логически на основе ключа, каждый раздел может быть обработан независимо, например, удалён. Это позволяет пользователям перемещать разделы, а следовательно, подмножества, между уровнями хранения эффективно по времени или удалять данные/удалять из кластера. Например, ниже мы удаляем посты с 2008 года:
- Оптимизация запросов - Хотя разделы могут помочь с производительностью запросов, это зависит в значительной степени от образцов доступа. Если запросы нацелены только на несколько разделов (в идеале один), производительность может быть потенциально улучшена. Это полезно только в том случае, если ключ разбиения не находится в первичном ключе и вы фильтруете по нему. Однако запросы, которые должны покрывать много разделов, могут производить хуже, чем если бы разделение не использовалось (так как может быть больше частей, как результат разделения). Преимущество нацеливания на единственный раздел будет еще менее выраженным до несуществования, если ключ разбиения уже является ранней записью в первичном ключе. Разделение также может использоваться для оптимизации
GROUP BYзапросов, если значения в каждом разделе уникальны. Однако в общем, пользователи должны обеспечивать, чтобы первичный ключ был оптимизирован и только рассматривать разбиение как технику оптимизации запросов в исключительных случаях, когда образцы доступа охватывают конкретное предсказуемое подмножество дня, например, разбиение по дню, с большинством запросов в последний день.
Рекомендации
Пользователи должны рассматривать разбиение как технику управления данными. Это идеально подходит, когда данные нужно удалять из кластера при работе с данными временных рядов, например, самый старый раздел можно просто удалить.
Важно: Убедитесь, что ваше выражение для ключа разбиения не приводит к созданию множества с высокой кардинальностью, i.e. создание более чем 100 разделов следует избегать. Например, не разбивайте свои данные по столбцам с высокой кардинальностью, таким как идентификаторы клиентов или имена. Вместо этого сделайте идентификатор клиента или имя первым столбцом в выражении ORDER BY.
Внутренне ClickHouse создаёт части для вставленных данных. По мере вставки данных количество частей увеличивается. Чтобы предотвратить чрезмерно большое количество частей, что ухудшит производительность запросов (поскольку больше файлов для чтения), части объединяются в фоновом асинхронном процессе. Если количество частей превышает предконфигурированный лимит, тогда ClickHouse выбросит исключение при вставке как "слишком много частей" ошибка. Это не должно происходить при нормальной работе и происходит только если ClickHouse неправильно настроен или используется неправильно, например, много маленьких вставок. Поскольку части создаются для каждого раздела изолированно, увеличение числа разделов вызывает увеличение количества частей, i.e. это множитель числа разделов. Высокая кардинальность ключей разбиения, следовательно, может вызвать эту ошибку и следует избегать.
Материализованные представления против проекций
Концепция проекций в ClickHouse позволяет пользователям указывать несколько ORDER BY предложений для таблицы.
В моделировании данных ClickHouse мы исследуем, как материализованные представления могут использоваться в ClickHouse для предварительного вычисления агрегаций, преобразования строк и оптимизации запросов для различных способов доступа. В последнем случае мы предложили пример, где материализованное представление отправляет строки в целевую таблицу с другим порядковым ключом, чем у оригинальной таблицы, принимающей вставки.
Например, рассмотрим следующий запрос:
Этот запрос требует сканирования всех 90 миллионов строк (примечательно, что быстро), так как UserId не является порядковым ключом. Ранее мы решали эту проблему с помощью материализованного представления, действующего как поиск для PostId. Та же проблема может быть решена с помощью проекции. Команда ниже добавляет проекцию для ORDER BY user_id.
Обратите внимание, что мы сначала должны создать проекцию, а затем материализовать её. Эта последняя команда приводит к тому, что данные хранятся дважды на диске в двух разных порядках. Проекция также может быть определена при создании данных, как показано ниже, и будет автоматически поддерживаться по мере вставки данных.
Если проекция создается через команду ALTER, создание асинхронно при выдаче команды MATERIALIZE PROJECTION. Пользователи могут подтвердить прогресс этой операции с помощью следующего запроса, ожидая is_done=1.
Если повторить вышеуказанный запрос, мы можем увидеть, что производительность значительно улучшилась за счёт дополнительного хранения.
С помощью команды EXPLAIN, мы также подтверждаем, что проекция была использована для выполнения этого запроса:
Когда использовать проекции
Проекции обеспечивают своё привлекательное преимущество для новых пользователей, так как они автоматически поддерживаются по мере поступления данных. Кроме того, запросы могут просто отправляться на одну таблицу, где проекции используются по возможности для ускорения времени ответа.
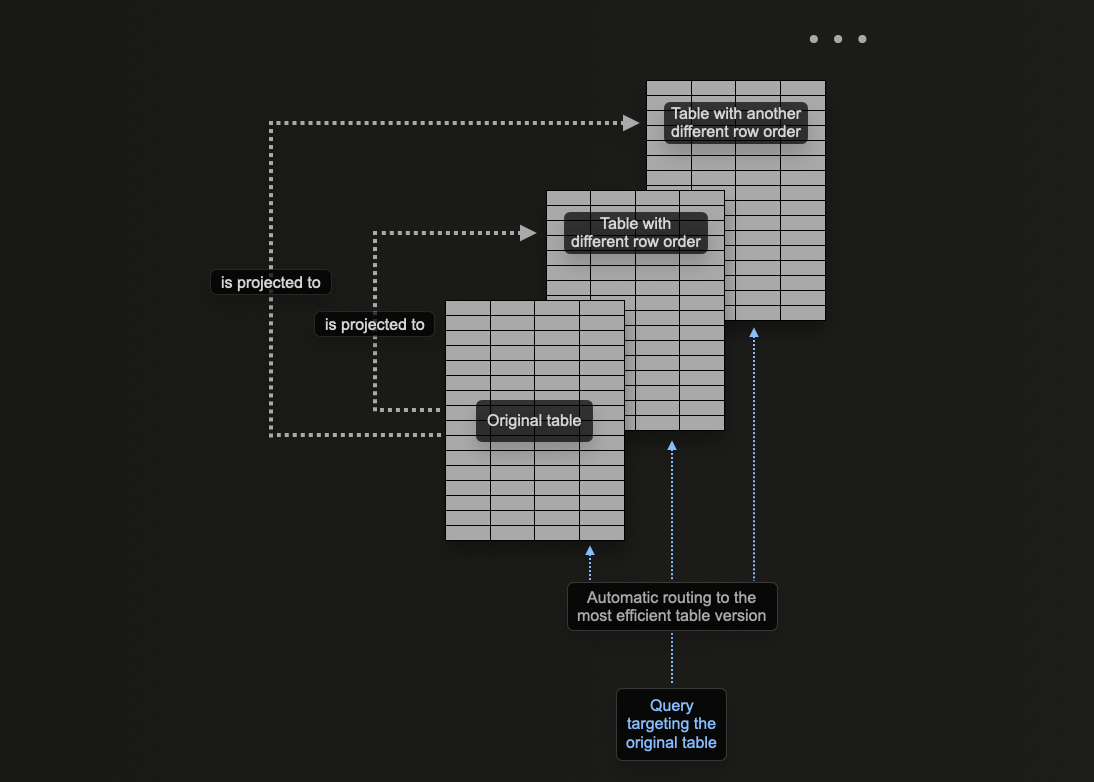
Это контрастирует с материализованными представлениями, где пользователь должен выбрать соответствующую оптимизированную целевую таблицу или переписать свой запрос в зависимости от применяемых фильтров. Это увеличивает акцент на пользовательские приложения и добавляет сложность на стороне клиента.
Несмотря на эти преимущества, проекции имеют некоторые присущие ограничения, о которых пользователи должны быть в курсе и, следовательно, должны применяться умеренно:
- Проекции не позволяют использовать разные TTL для исходной таблицы и (скрытой) целевой таблицы. Материализованные представления допускают разные TTL.
- Проекции в настоящее время не поддерживают
optimize_read_in_orderдля (скрытой) целевой таблицы. - Легковесные обновления и удаления не поддерживаются для таблиц с проекциями.
- Материализованные представления могут быть объединены в цепочку: целевая таблица одного материализованного представления может быть исходной таблицей для другого материализованного представления и так далее. Это не возможно с проекциями.
- Проекции не поддерживают соединения; материализованные представления поддерживают.
- Проекции не поддерживают фильтры (
WHEREусловие); материализованные представления поддерживают.
Мы рекомендуем использовать проекции, когда:
- Требуется полное переупорядочивание данных. Хотя выражение в проекции может, теоретически, использовать
GROUP BY,материализованные представления более эффективно подходят для поддержания агрегаций. Оптимизатор запросов также с большей вероятностью использует проекции, которые используют простое переупорядочивание, т.е.SELECT * ORDER BY x. Пользователи могут выбрать подмножество столбцов в этом выражении, чтобы уменьшить занимаемое хранилище. - Пользователи готовы принять с этим связаное увеличение занимаемого хранилища и затраты на запись данных дважды. Проведите тесты влияния на скорость вставки и оцените перерасход хранилища.
Переписывание запросов BigQuery в ClickHouse
Ниже приводятся примеры запросов, сравнивающих BigQuery с ClickHouse. Этот список имеет целью показать, как использовать возможности ClickHouse для значительного упрощения запросов. Примеры здесь используют полный набор данных Stack Overflow (до апреля 2024 года).
Пользователи (с более чем 10 вопросами), которые получают наибольшее количество просмотров:
BigQuery
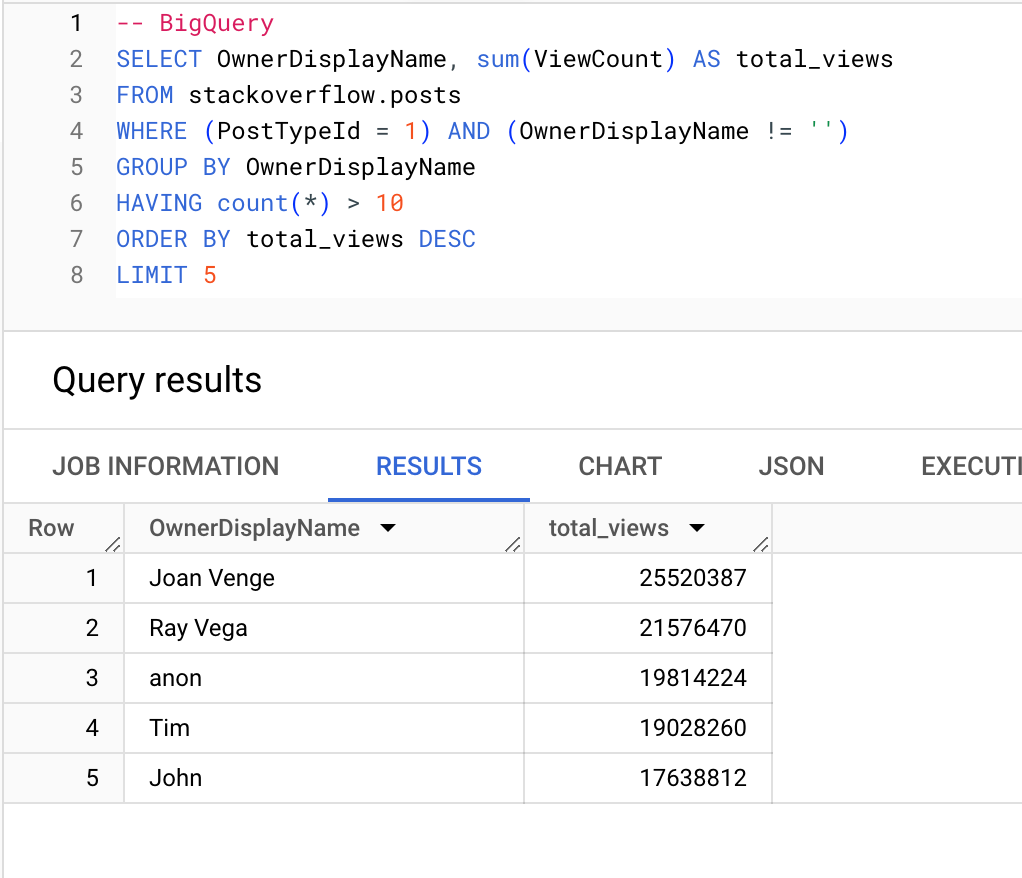
ClickHouse
Какие теги получают наибольшее количество просмотров:
BigQuery
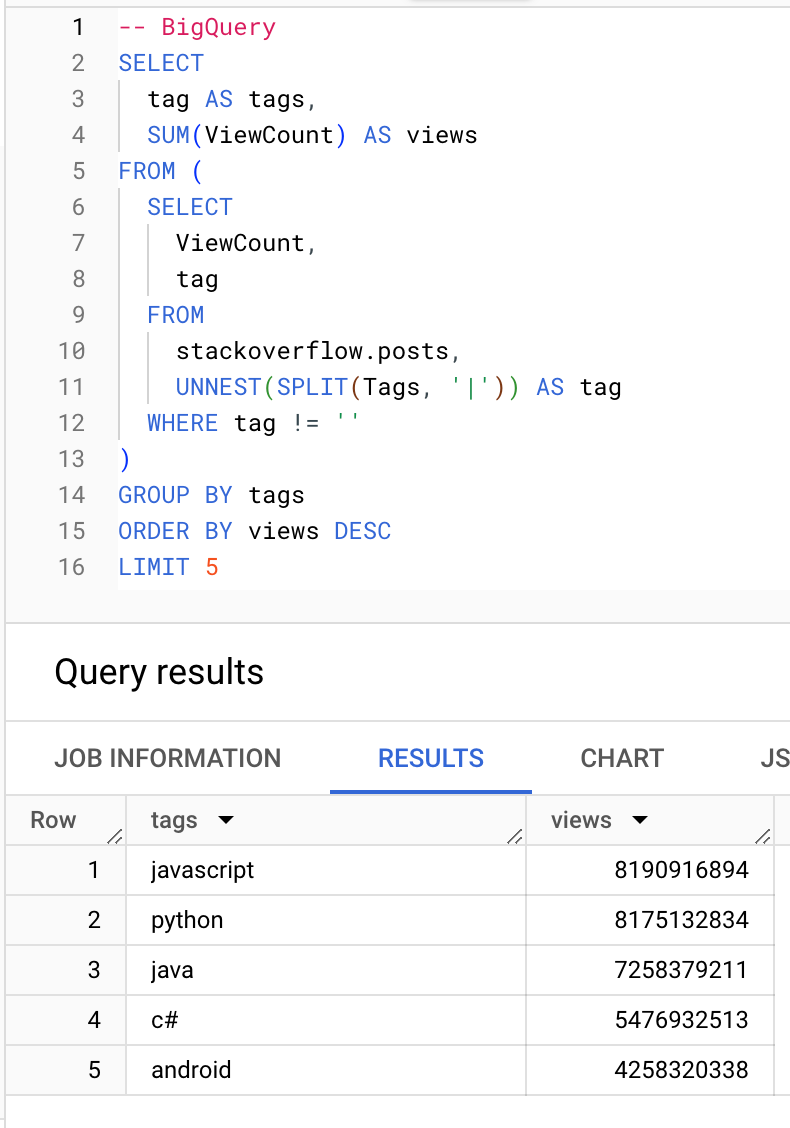
ClickHouse
Агрегатные функции
По возможности, пользователи должны использовать агрегатные функции ClickHouse. Ниже мы показываем использование функции argMax для вычисления наиболее просматриваемого вопроса каждого года.
BigQuery
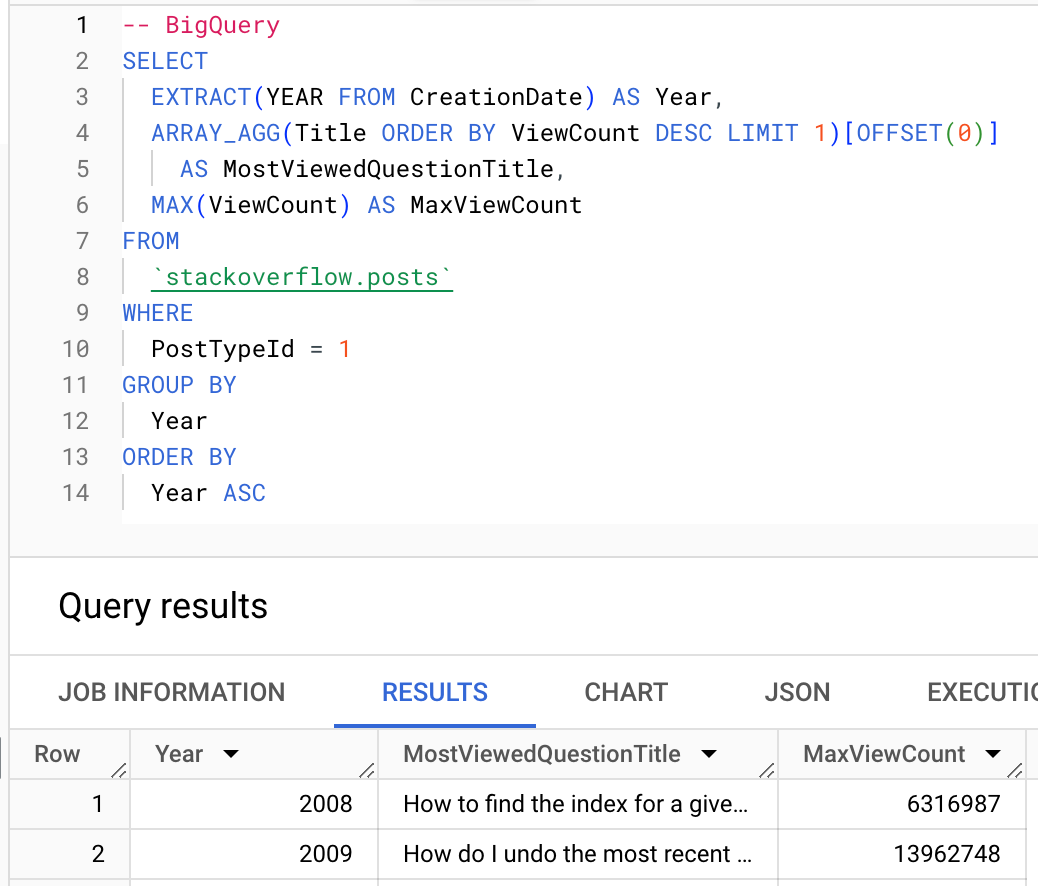

ClickHouse
Условные операторы и массивы
Условные и массивные функции значительно упрощают запросы. Следующий запрос вычисляет теги (с более чем 10000 вхождений), которые показали наибольший процентный рост с 2022 по 2023 год. Обратите внимание, насколько лаконичен следующий запрос ClickHouse благодаря условным операторам, массивным функциям и возможности повторного использования алиасов в условиях HAVING и SELECT.
BigQuery
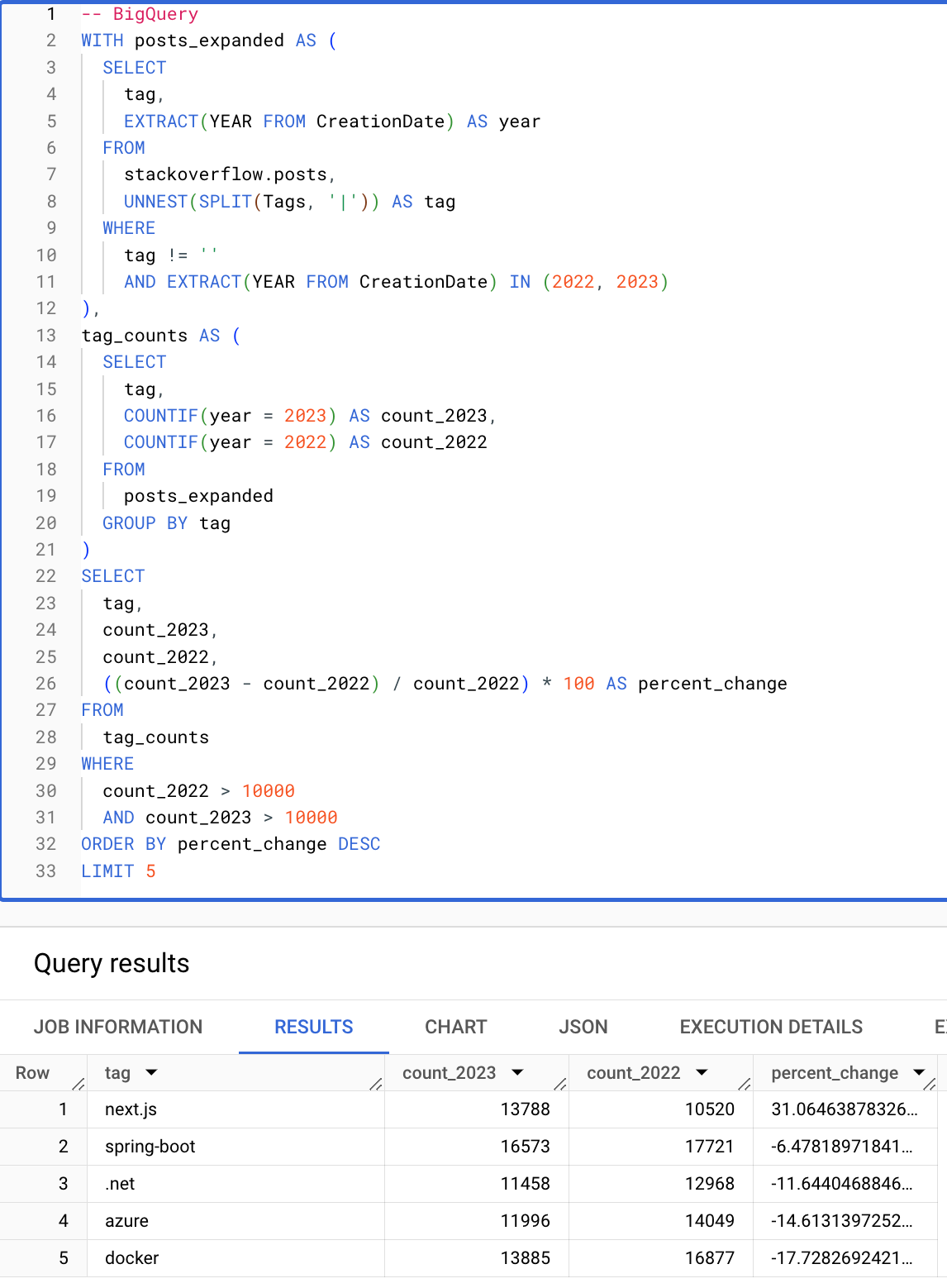
ClickHouse
Это завершает наше базовое руководство для пользователей, мигрирующих с BigQuery на ClickHouse. Мы рекомендуем пользователям, мигрирующим с BigQuery, ознакомиться с руководством по моделированию данных в ClickHouse для изучения более продвинутых функций ClickHouse.