Обновляемое материализованное представление
Обновляемые материализованные представления концептуально похожи на материализованные представления в традиционных OLTP базах данных, сохраняя результаты заданного запроса для быстрого извлечения и уменьшая необходимость многократного выполнения ресурсоемких запросов. В отличие от инкрементных материализованных представлений ClickHouse, это требует периодического выполнения запроса по всему набору данных - результаты которого хранятся в целевой таблице для запросов. Этот набор результатов, теоретически, должен быть меньше оригинального набора данных, что позволяет последующему запросу выполняться быстрее.
Диаграмма объясняет, как работают обновляемые материализованные представления:
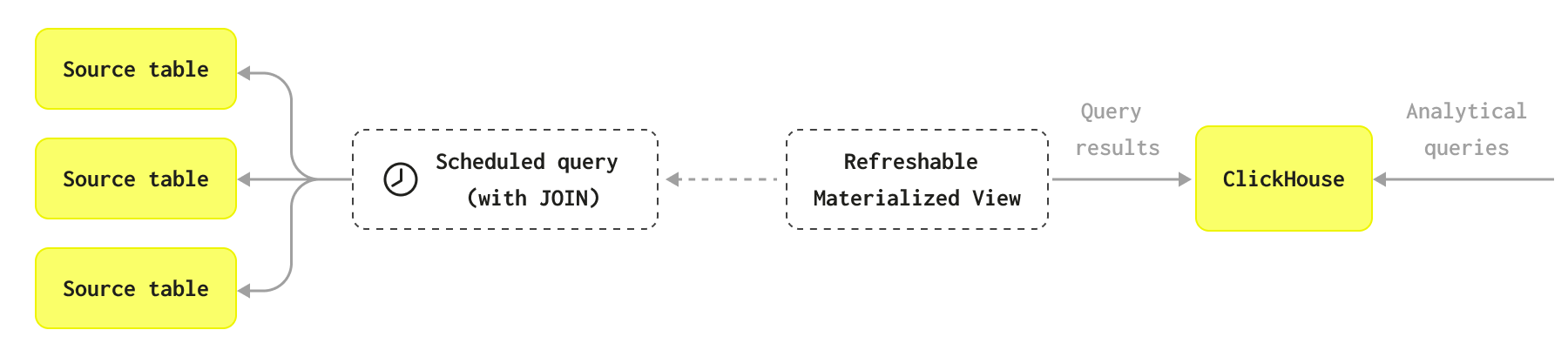
Вы также можете посмотреть следующее видео:
Когда следует использовать обновляемые материализованные представления?
Инкрементные материализованные представления ClickHouse являются чрезвычайно мощными и, как правило, масштабируются гораздо лучше, чем подход, используемый обновляемыми материализованными представлениями, особенно в случаях, когда необходимо выполнить агрегацию по одной таблице. Вычисляя агрегацию только по каждому блоку данных по мере его вставки и объединяя инкрементные состояния в конечной таблице, запрос всегда выполняется только на подмножестве данных. Этот метод масштабируется до потенциально петабайтов данных и обычно является предпочтительным методом.
Тем не менее, существуют случаи, когда этот инкрементный процесс не требуется или не применим. Некоторые проблемы либо несовместимы с инкрементным подходом, либо не требуют обновлений в реальном времени, что делает периодическое восстановление более подходящим. Например, вы можете регулярно выполнять полное пересчитывание представления по всему набору данных, потому что оно использует сложное соединение, которое не совместимо с инкрементным подходом.
Обновляемые материализованные представления могут запускать пакетные процессы, выполняющие такие задачи, как денормализация. Можно создать зависимости между обновляемыми материализованными представлениями так, что одно представление зависит от результатов другого и запускается только после его завершения. Это может заменить запланированные рабочие процессы или простые DAG, такие как работа dbt. Чтобы узнать больше о том, как установить зависимости между обновляемыми материализованными представлениями, перейдите на CREATE VIEW, в раздел
Dependencies.
Как обновить обновляемое материализованное представление?
Обновляемые материализованные представления обновляются автоматически с интервалом, который определяется при создании. Например, следующее материализованное представление обновляется каждую минуту:
Если вы хотите принудительно обновить материализованное представление, вы можете использовать оператор SYSTEM REFRESH VIEW:
Вы также можете отменить, остановить или запустить представление. Для получения дополнительной информации см. документацию по управлению обновляемыми материализованными представлениями.
Когда последний раз обновлялось обновляемое материализованное представление?
Чтобы узнать, когда в последний раз обновлялось обновляемое материализованное представление, вы можете выполнить запрос к системной таблице system.view_refreshes, как показано ниже:
Как изменить частоту обновления?
Чтобы изменить частоту обновления обновляемого материализованного представления, используйте синтаксис ALTER TABLE...MODIFY REFRESH.
После этого вы можете использовать Когда последний раз обновлялось обновляемое материализованное представление? запрос, чтобы проверить, что частота была обновлена:
Использование APPEND для добавления новых строк
Функциональность APPEND позволяет вам добавлять новые строки в конец таблицы, а не заменять целое представление.
Одним из применений этой функции является захват снимков значений на определенный момент времени. Например, предположим, что у нас есть таблица events, заполняемая потоком сообщений из Kafka, Redpanda или другой платформы потоковых данных.
Этот набор данных имеет 4096 значений в колонке uuid. Мы можем написать следующий запрос для поиска значений с наибольшим общим количеством:
Предположим, что мы хотим захватить количество для каждого uuid каждые 10 секунд и сохранить это в новой таблице под названием events_snapshot. Схема events_snapshot будет выглядеть следующим образом:
Затем мы можем создать обновляемое материализованное представление для заполнения этой таблицы:
Затем мы можем выполнить запрос к events_snapshot, чтобы получить количество с течением времени для конкретного uuid:
Примеры
Теперь давайте рассмотрим, как использовать обновляемые материализованные представления с некоторыми примерами наборов данных.
Stack Overflow
Руководство по денормализации данных демонстрирует различные техники денормализации данных с использованием набора данных Stack Overflow. Мы заполняем данные в следующие таблицы: votes, users, badges, posts и postlinks.
В этом руководстве мы показали, как денормализовать набор данных postlinks в таблицу posts с помощью следующего запроса:
Затем мы показали, как выполнить одноразовую вставку этих данных в таблицу posts_with_links, но в производственной системе мы хотели бы выполнять эту операцию периодически.
Обе таблицы posts и postlinks могут потенциально обновляться. Поэтому, вместо того, чтобы пытаться реализовать это объединение с помощью инкрементных материализованных представлений, может быть достаточно просто запланировать выполнение этого запроса через определенные интервалы, например, раз в час, сохраняя результаты в таблице post_with_links.
Вот где обновляемое материализованное представление помогает, и мы можем создать его с помощью следующего запроса:
Представление будет выполняться немедленно и каждые часы впоследствии, как настроено, чтобы гарантировать отражение обновлений в исходной таблице. Важно, что когда запрос повторно выполняется, набор результатов атомарно и прозрачно обновляется.
Синтаксис здесь идентичен инкрементному материализованному представлению, за исключением того, что мы включаем REFRESH клаузу:
IMDb
В руководстве по интеграции dbt и ClickHouse мы заполнили набор данных IMDb следующими таблицами: actors, directors, genres, movie_directors, movies и roles.
Затем мы можем написать следующий запрос, который можно использовать для вычисления сводки для каждого актера, отсортированной по количеству его появлений в фильмах.
Не занимает много времени для возврата результата, но давайте представим, что мы хотим сделать это еще быстрее и менее затратным по вычислениям. Предположим, что этот набор данных также подвергается постоянным обновлениям - фильмы постоянно выходят, новые актеры и директора также появляются.
Пришло время для обновляемого материализованного представления, поэтому сначала давайте создадим целевую таблицу для результатов:
Теперь мы можем определить представление:
Представление будет выполняться немедленно и каждую минуту впоследствии, как настроено, чтобы гарантировать отражение обновлений в исходной таблице. Наш предыдущий запрос на получение сводки актеров становится синтаксически проще и значительно быстрее!
Предположим, что мы добавляем нового актера, "Clicky McClickHouse" в наши исходные данные, который, оказывается, снялся во множестве фильмов!
Менее чем через 60 секунд наша целевая таблица обновляется, чтобы отразить плодовитую природу актерства Clicky: