Сравнение PostgreSQL и ClickHouse
Postgres vs ClickHouse: Эквивалентные и различные концепции
Пользователи, переходящие с OLTP-систем, которые привыкли к ACID-транзакциям, должны быть осведомлены о том, что ClickHouse сознательно делает компромиссы, не обеспечивая полного их представления в обмен на производительность. Семантика ClickHouse может обеспечить высокие гарантии долговечности и высокую скорость записи, если она будет хорошо понята. Ниже мы выделяем несколько ключевых концепций, с которыми пользователи должны быть знакомы перед тем, как начать работать с ClickHouse после PostgreSQL.
Шарды против реплик
Шардирование и репликация — это две стратегии, используемые для масштабирования за пределами одной инстанции PostgreSQL, когда хранилище и/или вычислительные ресурсы становятся узким местом в производительности. Шардирование в PostgreSQL включает разделение большой базы данных на более мелкие и управляемые части, распределенные между несколькими узлами. Однако PostgreSQL не поддерживает шардирование нативно. Вместо этого шардирование можно достичь с помощью расширений, таких как Citus, в котором PostgreSQL становится распределенной базой данных с возможностью горизонтального масштабирования. Этот подход позволяет PostgreSQL обрабатывать более высокие скорости транзакций и большие наборы данных, распределяя нагрузку по нескольким машинам. Шарды могут быть основаны на строках или схемах, чтобы предоставить гибкость для типов рабочей нагрузки, таких как транзакционные или аналитические. Шардирование может ввести значительную сложность в управление данными и выполнение запросов, так как требует координации между несколькими машинами и гарантии согласованности.
В отличие от шардов, реплики — это дополнительные инстанции PostgreSQL, которые содержат все или некоторые данные от основного узла. Реплики используются по различным причинам, включая улучшение производительности чтения и сценарии высокой доступности (HA). Физическая репликация — это встроенная функция PostgreSQL, которая включает в себя копирование всей базы данных или значительных ее частей на другой сервер, включая все базы данных, таблицы и индексы. Это включает потоковую передачу сегментов WAL с основного узла к репликам по TCP/IP. В отличие от этого, логическая репликация — это более высокий уровень абстракции, который передает изменения, основанные на операциях INSERT, UPDATE и DELETE. Хотя те же результаты могут применяться к физической репликации, логическая репликация предоставляет большую гибкость для нацеливания на конкретные таблицы и операции, а также для преобразования данных и поддержки различных версий PostgreSQL.
В отличие от этого, шардирование и репликация ClickHouse — это две ключевые концепции, связанные с распределением данных и избыточностью. Реплики ClickHouse можно рассматривать как аналоговые к репликам PostgreSQL, хотя репликация в ClickHouse является в конечном итоге согласованной без понятия первичного узла. В отличие от PostgreSQL, шардирование в ClickHouse поддерживается нативно.
Шард — это часть данных вашей таблицы. У вас всегда есть как минимум один шард. Шардирование данных между несколькими серверами может использоваться для разделения нагрузки, если вы превышаете емкость одного сервера с использованием всех шардов для выполнения запроса параллельно. Пользователи могут вручную создавать шарды для таблицы на разных серверах и вставлять данные непосредственно в них. В качестве альтернативы можно использовать распределенную таблицу с ключом шардирования, определяющим, к какому шару направляются данные. Ключ шардирования может быть случайным или являться результатом хеш-функции. Важно, что шард может состоять из нескольких реплик.
Реплика — это копия ваших данных. ClickHouse всегда имеет как минимум одну копию ваших данных, поэтому минимальное количество реплик равно одному. Добавление второй реплики ваших данных обеспечивает отказоустойчивость и потенциально дополнительную вычислительную мощность для обработки большего количества запросов ( Параллельные реплики также могут использоваться для распределения вычислений для одного запроса, тем самым снижая задержку). Реплики достигаются с помощью движка таблиц ReplicatedMergeTree, который позволяет ClickHouse поддерживать несколько копий данных синхронизированными между различными серверами. Репликация является физической: только сжатые части передаются между узлами, а не запросы.
В заключение, реплика — это копия данных, обеспечивающая избыточность и надежность (и потенциально распределенную обработку), в то время как шард — это подмножество данных, позволяющее распределенную обработку и балансировку нагрузки.
ClickHouse Cloud использует одну копию данных, поддерживаемую в S3 с несколькими вычислительными репликами. Данные доступны для каждого узла-реплики, каждый из которых имеет локальный SSD-кеш. Это зависит только от репликации метаданных через ClickHouse Keeper.
Консистентность в конечном итоге
ClickHouse использует ClickHouse Keeper (реализация ZooKeeper на C++), который управляет внутренним механизмом репликации, сосредотачиваясь в первую очередь на хранении метаданных и обеспечивая конечную согласованность. Keeper используется для назначения уникальных последовательных номеров для каждой вставки в распределенной среде. Это имеет решающее значение для поддержания порядка и согласованности операций. Эта структура также обрабатывает фоновые операции, такие как слияния и мутации, обеспечивая распределение работы по этим операциям и гарантируя их выполнение в одном и том же порядке на всех репликах. В дополнение к метаданным, Keeper функционирует как комплексный контрольный центр для репликации, включая отслеживание контрольных сумм для хранящихся частей данных и действует как распределенная система уведомлений между репликами.
Процесс репликации в ClickHouse (1) начинается, когда данные вставляются в любую реплику. Эти данные, в своем сыром виде вставки, (2) записываются на диск вместе с их контрольными суммами. После записи реплика (3) пытается зарегистрировать эту новую часть данных в Keeper, выделяя уникальный номер блока и регистрируя детали новой части. Другие реплики при (4) обнаружении новых записей в журнале репликации (5) загружают соответствующую часть данных через внутренний протокол HTTP, проверяя ее на соответствие контрольным суммам, указанным в ZooKeeper. Этот метод гарантирует, что все реплики в конечном итоге имеют согласованные и актуальные данные, несмотря на различные скорости обработки или потенциальные задержки. Более того, система способна обрабатывать несколько операций одновременно, оптимизируя процессы управления данными и позволяя масштабируемость системы и устойчивость к сбоям аппаратного обеспечения.
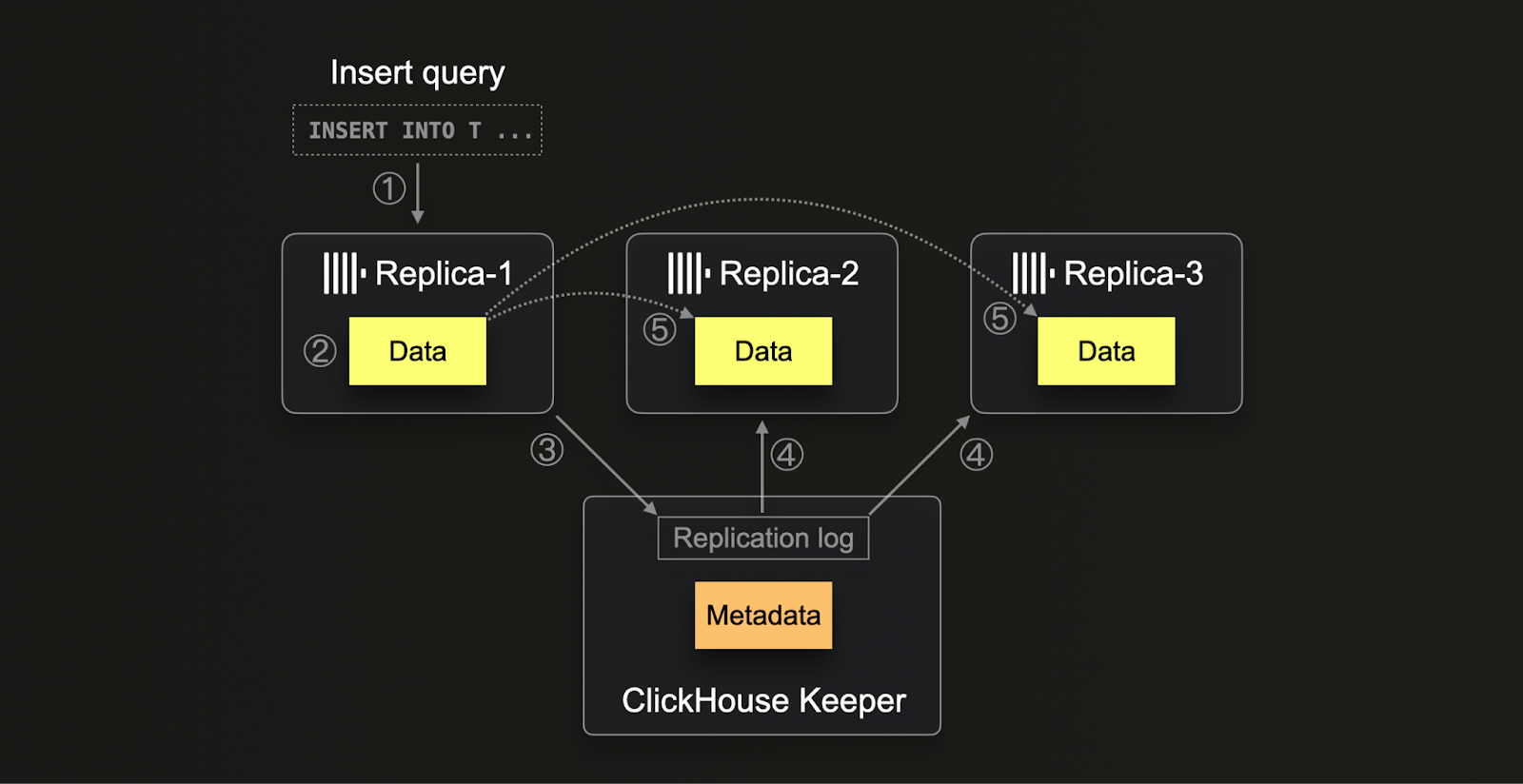
Обратите внимание, что ClickHouse Cloud использует механизм репликации, оптимизированный для облака, адаптированный к архитектуре разделения хранения и вычислений. Путем хранения данных в общем объектном хранилище данные автоматически доступны для всех вычислительных узлов без необходимости физической репликации данных между узлами. Вместо этого Keeper используется только для обмена метаданными (какие данные где находятся в объектном хранилище) между вычислительными узлами.
PostgreSQL использует другую стратегию репликации по сравнению с ClickHouse, в основном применяя потоковую репликацию, которая включает модель первичного узла, где данные непрерывно передаются с первичного узла на один или несколько узлов-реплик. Этот тип репликации обеспечивает почти реальную консистентность и может быть синхронным или асинхронным, что дает администраторам контроль над балансом между доступностью и согласованностью. В отличие от ClickHouse, PostgreSQL полагается на WAL (журнал предварительной записи) с логической репликацией и декодированием, чтобы передавать объекты данных и изменения между узлами. Этот подход в PostgreSQL более прямолинеен, но может не предложить того же уровня масштабируемости и отказоустойчивости в высокораспределенных средах, которые ClickHouse достигает благодаря сложному использованию Keeper для координации распределенных операций и конечной согласованности.
Влияние на пользователя
В ClickHouse существует возможность грязных чтений — когда пользователи могут записывать данные в одну реплику, а затем считывать потенциально не реплицированные данные из другой — из-за модели репликации, обеспечивающей конечную согласованность, управляемой через Keeper. Эта модель подчеркивает производительность и масштабируемость в распределенных системах, позволяя репликам работать независимо и синхронизироваться асинхронно. В результате новые вставленные данные могут быть не сразу видны на всех репликах в зависимости от задержки репликации и времени, необходимого для распространения изменений по системе.
С другой стороны, модель потоковой репликации PostgreSQL, как правило, может предотвратить грязные чтения, применяя синхронные варианты репликации, при которых первичный узел ждет, пока как минимум одна реплика подтвердит получение данных перед завершением транзакции. Это гарантирует, что после завершения транзакции существует гарантия, что данные доступны в другой реплике. В случае сбоя первичного узла реплика гарантирует, что запросы видят подтвержденные данные, тем самым поддерживая более строгий уровень согласованности.
Рекомендации
Пользователи, впервые знакомящиеся с ClickHouse, должны быть осведомлены о этих различиях, которые проявятся в реплицированных средах. Обычно конечная согласованность достаточно в аналитике по миллиарду, если не триллионному, объемам данных — где метрики либо более стабильны, либо оценка достаточна, поскольку новые данные постоянно вставляются с высокой скоростью.
Существуют несколько вариантов для повышения согласованности чтений в случае необходимости. Оба примера требуют либо увеличения сложности, либо накладных расходов — снижая производительность запросов и затрудняя масштабирование ClickHouse. Мы рекомендуем эти подходы только в случае крайней необходимости.
Последовательная маршрутизация
Чтобы преодолеть некоторые ограничения конечной согласованности, пользователи могут гарантировать, что клиенты направляются к одним и тем же репликам. Это полезно в случаях, когда несколько пользователей выполняют запросы к ClickHouse и результаты должны быть детерминированными по запросам. Хотя результаты могут отличаться по мере вставки новых данных, следует запрашивать одни и те же реплики, обеспечивая согласованный обзор.
Это можно достигнуть несколькими способами в зависимости от вашей архитектуры и используете ли вы ClickHouse OSS или ClickHouse Cloud.
ClickHouse Cloud
ClickHouse Cloud использует одну копию данных, поддерживаемую в S3 с несколькими вычислительными репликами. Данные доступны для каждого узла-реплики, который имеет локальный SSD-кеш. Чтобы гарантировать согласованные результаты, пользователи должны лишь убедиться в согласованной маршрутизации на один и тот же узел.
Связь с узлами службы ClickHouse Cloud происходит через прокси. Соединения по HTTP и нативному протоколу будут направлены на один и тот же узел в течение времени, в течение которого они остаются открытыми. В случае соединений HTTP 1.1 от большинства клиентов это зависит от окна Keep-Alive. Эту настройку можно конфигурировать на большинстве клиентов, например, Node Js. Это также требует конфигурации на стороне сервера, которая будет выше чем у клиента и установлена на 10 секунд в ClickHouse Cloud.
Чтобы гарантировать согласованное маршрутизирование между соединениями, например, если используется пул соединений или если соединения истекают, пользователи могут обеспечить использование одного и того же соединения (проще для нативного протокола) или запросить открытие липких конечных точек. Это предоставляет набор конечных точек для каждого узла в кластере, тем самым позволяя клиентам гарантировать, что запросы направляются детерминированно.
Свяжитесь с поддержкой для доступа к липким конечным точкам.
ClickHouse OSS
Достигнуть такого поведения в OSS зависит от вашей топологии шардов и реплик и используете ли вы Распределенную таблицу для выполнения запросов.
Когда у вас только один шард и реплики (что обычно, так как ClickHouse вертикально масштабируется), пользователи выбирают узел на уровне клиента и напрямую запрашивают реплику, обеспечивая, что выбор детерминирован.
Хотя топологии с несколькими шардом и репликами возможны без использования распределенной таблицы, такие расширенные развертывания, как правило, имеют свою собственную инфраструктуру маршрутизации. Поэтому мы предполагаем, что развертывания с более чем одним шардом используют распределенные таблицы (распределенные таблицы могут использоваться с развертываниями с одним шаром, но обычно это не нужно).
В этом случае пользователи должны убедиться, что осуществляется согласованная маршрутизация узлов на основе свойства, например session_id или user_id. Настройки prefer_localhost_replica=0 и load_balancing=in_order должны быть установлены в запросе. Это гарантирует, что любые локальные реплики шардов предпочтительнее, при этом реплики будут предпочтительны в порядке, указанном в конфигурации, если до тех пор они имеют одинаковое количество ошибок — переключение произойдет с помощью случайного выбора, если ошибок больше. load_balancing=nearest_hostname также может использоваться как альтернатива для этого детерминированного выбора шардов.
При создании распределенной таблицы пользователи укажут кластер. Определение этого кластера, указанного в config.xml, перечислит шардов (и их реплики) — таким образом, пользователи смогут контролировать порядок, в котором они используются с каждого узла. Используя это, пользователи могут обеспечить выбор детерминированным.
Последовательная согласованность
В исключительных случаях пользователям может понадобиться последовательная согласованность.
Последовательная согласованность в базах данных — это когда операции в базе данных кажутся выполняемыми в некотором последовательном порядке, и этот порядок согласован для всех процессов, взаимодействующих с базой данных. Это означает, что каждая операция, кажется, принимается к действию мгновенно между ее вызовом и завершением, и существует единый, согласованный порядок, в котором все операции наблюдаются любым процессом.
С точки зрения пользователя это типично проявляется в необходимости записывать данные в ClickHouse и при чтении данных гарантировать, что возвращаются последние вставленные строки. Это можно достичь несколькими способами (в порядке предпочтения):
- Чтение/Запись на одном узле — Если вы используете нативный протокол или сессию для выполнения вашей записи/чтения через HTTP, вы должны будете быть подключены к одной и той же реплике: в этом случае вы читаете напрямую с узла, на который записываете, тогда ваше чтение всегда будет согласованным.
- Синхронизация реплик вручную — Если вы записываете на одну реплику и читаете с другой, вы можете использовать команду
SYSTEM SYNC REPLICA LIGHTWEIGHTперед чтением. - Включить последовательную согласованность — с помощью настройки запроса
select_sequential_consistency = 1. В OSS также должна быть указана настройкаinsert_quorum = 'auto'.
Смотрите здесь для получения дополнительных сведений о включении этих настроек.
Использование последовательной согласованности создаст большую нагрузку на ClickHouse Keeper. Результат может значить более медленные вставки и чтения. SharedMergeTree, используемый в ClickHouse Cloud в качестве основного движка таблиц, последовательная согласованность вызывает меньше накладных расходов и будет лучше масштабироваться. Пользователи OSS должны использовать этот подход осторожно и измерять нагрузку на Keeper.
Поддержка транзакций (ACID)
Пользователи, мигрирующие с PostgreSQL, могут быть знакомы с его надежной поддержкой свойств ACID (Атомарность, Согласованность, Изолированность, Долговечность), что делает его надежным выбором для транзакционных баз данных. Атомарность в PostgreSQL гарантирует, что каждая транзакция рассматривается как единое целое, которое либо полностью успешно, либо полностью откатывается, предотвращая частичное обновление. Согласованность поддерживается путем обеспечения ограничений, триггеров и правил, которые гарантируют, что все транзакции базы данных приводят к допустимому состоянию. Уровни изоляции, от Read Committed до Serializable, поддерживаются в PostgreSQL, позволяя точно контролировать видимость изменений, сделанных конкурентными транзакциями. Наконец, Долговечность достигается с помощью журналов предварительной записи (WAL), что гарантирует, что после успешной транзакции она останется такой, даже в случае сбоя системы.
Эти свойства характерны для OLTP баз данных, выступающих в роли источника истины.
Хотя они мощны, это также связано с присущими ограничениями и делает сложным использование PB-скалов. ClickHouse идет на компромиссы в этих свойствах, чтобы обеспечить быструю аналитическую работу в больших объемах, поддерживая высокую скорость записи.
ClickHouse предоставляет свойства ACID в ограниченных конфигурациях — проще всего при использовании экземпляра MergeTree без репликации с одним разделом. Пользователи не должны ожидать эти свойства за пределами этих случаев и должны убедиться, что они не являются обязательными требованиями.
Репликация или миграция данных Postgres с ClickPipes (powered by PeerDB)
PeerDB теперь доступен нативно в ClickHouse Cloud — Быстрая репликация Postgres в ClickHouse CDC с нашим новым коннектором ClickPipe — теперь в открытом бета-тестировании.
PeerDB позволяет вам без проблем реплицировать данные из PostgreSQL в ClickHouse. Вы можете использовать этот инструмент для
- непрерывной репликации с использованием CDC, позволяя PostgreSQL и ClickHouse сосуществовать — PostgreSQL для OLTP и ClickHouse для OLAP; и
- миграции из PostgreSQL в ClickHouse.