JDBC Connector
Этот коннектор следует использовать только в том случае, если ваши данные простые и состоят из примитивных типов данных, например, int. Специфичные для ClickHouse типы, такие как карты, не поддерживаются.
Для наших примеров мы используем дистрибутив Kafka Connect от Confluent.
Ниже мы описываем простую установку, извлечение сообщений из одной темы Kafka и вставку строк в таблицу ClickHouse. Мы рекомендуем Confluent Cloud, который предлагает щедрый бесплатный уровень для тех, у кого нет среды Kafka.
Обратите внимание, что для JDBC Connector требуется схема (вы не можете использовать простой JSON или CSV с JDBC коннектором). Хотя схема может быть закодирована в каждом сообщении; категорически рекомендуется использовать реестр схем Confluenty, чтобы избежать связанных накладных расходов. Предоставленный скрипт вставки автоматически выводит схему из сообщений и вставляет её в реестр - этот скрипт можно повторно использовать для других наборов данных. Ключи Kafka предполагаются как строки. Дополнительные сведения о схемах Kafka можно найти здесь.
Лицензия
JDBC Connector распространяется по Лицензии Сообщества Confluent
Шаги
Соберите данные для подключения
Чтобы подключиться к ClickHouse с помощью HTTP(S), вам нужна следующая информация:
-
ХОСТ и ПОРТ: как правило, порт составляет 8443 при использовании TLS или 8123 при отсутствии TLS.
-
НАЗВАНИЕ БАЗЫ ДАННЫХ: по умолчанию существует база данных с именем
default, используйте имя базы данных, к которой вы хотите подключиться. -
ИМЯ ПОЛЬЗОВАТЕЛЯ и ПАРОЛЬ: по умолчанию имя пользователя равно
default. Используйте имя пользователя, соответствующее вашему случаю.
Сведения о вашем ClickHouse Cloud-сервисе доступны в консоли ClickHouse Cloud. Выберите сервис, к которому вы будете подключаться, и нажмите Подключиться:
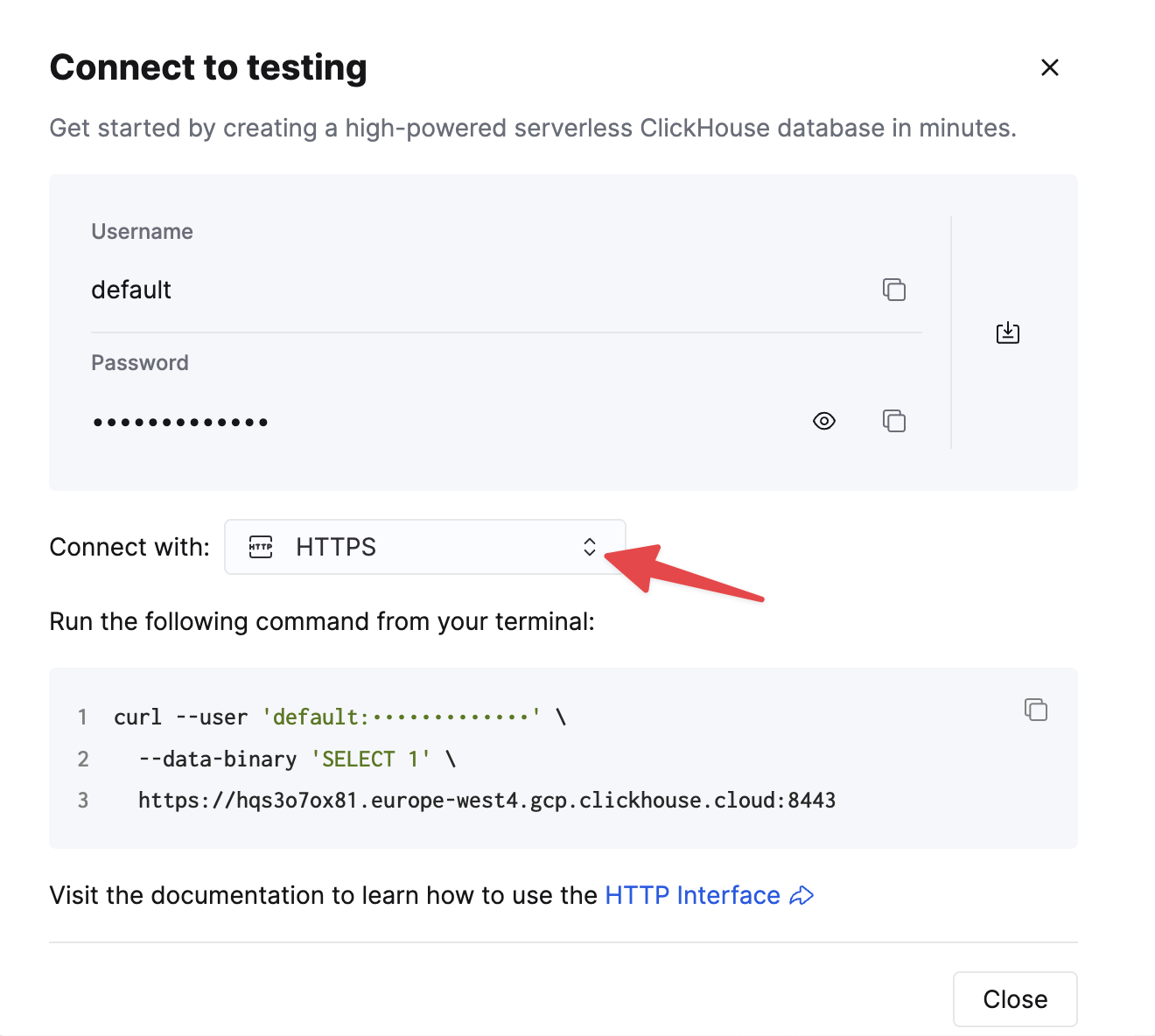
Выберите HTTPS, и детали доступны в примере команды curl.
Если вы используете самоуправляемый ClickHouse, детали подключения устанавливаются вашим администратором ClickHouse.
1. Установите Kafka Connect и Connector
Мы предполагаем, что вы скачали пакет Confluent и установили его локально. Следуйте инструкциям по установке коннектора, как описано здесь.
Если вы используете метод установки confluent-hub, ваши локальные файлы конфигурации будут обновлены.
Чтобы отправлять данные в ClickHouse из Kafka, мы используем компонент Sink коннектора.
2. Скачайте и установите JDBC Driver
Скачайте и установите драйвер JDBC ClickHouse clickhouse-jdbc-<version>-shaded.jar здесь. Установите его в Kafka Connect, следуя инструкциям здесь. Другие драйвера могут работать, но проверены не были.
Общая проблема: документация предлагает скопировать jar в share/java/kafka-connect-jdbc/. Если у вас возникают проблемы с тем, чтобы Connect нашел драйвер, скопируйте драйвер в share/confluent-hub-components/confluentinc-kafka-connect-jdbc/lib/. Либо измените plugin.path, чтобы включить драйвер - см. ниже.
3. Подготовьте конфигурацию
Следуйте этим инструкциям для настройки Connect, применимого к вашему типу установки, учитывая различия между независимым и распределенным кластером. Если вы используете Confluent Cloud, имеет значение распределенная настройка.
Следующие параметры имеют значение для использования JDBC коннектора с ClickHouse. Полный список параметров можно найти здесь:
_connection.url_- у этого параметра должна быть формаjdbc:clickhouse://<clickhouse host>:<clickhouse http port>/<target database>connection.user- пользователь с правами на запись в целевую базу данныхtable.name.format- таблица ClickHouse для вставки данных. Она должна существовать.batch.size- количество строк, отправляемых в одном пакете. Убедитесь, что это значение установлено на достаточно большое число. В соответствии с рекомендациями ClickHouse значение 1000 следует считать минимумом.tasks.max- JDBC Sink коннектор поддерживает выполнение одной или нескольких задач. Это может быть использовано для увеличения производительности. Вместе с размером пакета это является вашим основным способом улучшения производительности.value.converter.schemas.enable- Установите в false, если используете реестр схем; true, если вы встроили ваши схемы в сообщения.value.converter- Установите в зависимости от вашего типа данных, например, для JSON,io.confluent.connect.json.JsonSchemaConverter.key.converter- Установите вorg.apache.kafka.connect.storage.StringConverter. Мы используем строковые ключи.pk.mode- Не относится к ClickHouse. Установите в none.auto.create- Не поддерживается и должно быть false.auto.evolve- Мы рекомендуем false для этой настройки, хотя она может быть поддержана в будущем.insert.mode- Установите на "insert". Другие режимы в настоящее время не поддерживаются.key.converter- Установите в зависимости от типов ваших ключей.value.converter- Установите на основе типа данных в вашей теме. Эти данные должны иметь поддерживаемую схему - форматы JSON, Avro или Protobuf.
Если вы используете наш образец данных для тестирования, убедитесь, что установлены следующие параметры:
value.converter.schemas.enable- Установите в false, так как мы используем реестр схем. Установите в true, если вы встраиваете схему в каждое сообщение.key.converter- Установите на "org.apache.kafka.connect.storage.StringConverter". Мы используем строковые ключи.value.converter- Установите "io.confluent.connect.json.JsonSchemaConverter".value.converter.schema.registry.url- Установите на URL сервера схем вместе с учетными данными для сервера схем с использованием параметраvalue.converter.schema.registry.basic.auth.user.info.
Примеры конфигурационных файлов для данных образца Github можно найти здесь, при условии, что Connect работает в независимом режиме, а Kafka размещен в Confluent Cloud.
4. Создайте таблицу ClickHouse
Убедитесь, что таблица была создана, удалите её, если она уже существует из предыдущих примеров. Пример, совместимый с сокращенным набором данных Github, показан ниже. Обратите внимание на отсутствие любых типов Array или Map, которые в настоящее время не поддерживаются:
5. Запустите Kafka Connect
Запустите Kafka Connect в режиме независимом или распределенном.
6. Добавьте данные в Kafka
Вставьте сообщения в Kafka, используя скрипт и конфигурацию, предоставленные ранее. Вам нужно будет изменить github.config, чтобы включить ваши учетные данные Kafka. Скрипт в настоящее время настроен для использования с Confluent Cloud.
Этот скрипт можно использовать для вставки любого ndjson файла в тему Kafka. Он попытается автоматически вывести схему для вас. Образец предоставленной конфигурации вставит только 10 тысяч сообщений - измените здесь, если это необходимо. Эта конфигурация также удаляет любые несовместимые поля Array из набора данных во время вставки в Kafka.
Это необходимо для того, чтобы JDBC коннектор мог преобразовать сообщения в операторы INSERT. Если вы используете свои собственные данные, убедитесь, что вы либо вставляете схему с каждым сообщением (установив _value.converter.schemas.enable _в true), либо ваши клиенты публикуют сообщения с ссылкой на схему в реестре.
Kafka Connect должен начать потребление сообщений и вставку строк в ClickHouse. Обратите внимание, что предупреждения о "[Режим, соответствующий JDBC] Транзакция не поддерживается." ожидаемы и могут быть игнорированы.
Простое чтение из целевой таблицы "Github" должно подтвердить вставку данных.
Рекомендуемое дальнейшее чтение
- Параметры конфигурации Kafka Sink
- Глубокое погружение в Kafka Connect – JDBC Source Connector
- Глубокое погружение в Kafka Connect JDBC Sink: Работа с первичными ключами
- Kafka Connect в действии: JDBC Sink - для тех, кто предпочитает смотреть, а не читать.
- Глубокое погружение в Kafka Connect – Конвертеры и объяснение сериализации