Вставка данных в ClickHouse
Основной пример
Вы можете использовать знакомую команду INSERT INTO TABLE с ClickHouse. Давайте вставим данные в таблицу, которую мы создали в вводном руководстве "Создание таблиц в ClickHouse".
Чтобы убедиться, что это сработало, мы запустим следующий запрос SELECT:
Который возвращает:
Вставка в ClickHouse vs. OLTP базы данных
Как OLAP (Online Analytical Processing) база данных, ClickHouse оптимизирован для высокой производительности и масштабируемости, позволяя потенциально вставлять миллионы строк в секунду. Это достигается благодаря сочетанию высоко параллелизированной архитектуры и эффективного сжатия, ориентированного на столбцы, но с компромиссами по немедленной согласованности. Более конкретно, ClickHouse оптимизирован для операций только добавления и предлагает только гарантии окончательной согласованности.
В отличие от этого, OLTP базы данных, такие как Postgres, специально оптимизированы для транзакционных вставок с полной совместимостью ACID, обеспечивая сильные гарантии согласованности и надежности. PostgreSQL использует MVCC (Multi-Version Concurrency Control) для обработки параллельных транзакций, что включает в себя поддержку нескольких версий данных. Эти транзакции могут потенциально затрагивать небольшое количество строк за раз, при этом возникают значительные накладные расходы из-за гарантий надежности, ограничивающих производительность вставки.
Чтобы достичь высокой производительности вставки при поддержании сильных гарантии согласованности, пользователям следует придерживаться простых правил, описанных ниже, при вставке данных в ClickHouse. Соблюдение этих правил поможет избежать проблем, с которыми пользователи часто сталкиваются в первый раз, используя ClickHouse, и пытаться повторить стратегию вставки, которая работает для OLTP баз данных.
Рекомендации по вставкам
Вставляйте в большие пакеты
По умолчанию каждая вставка, отправленная в ClickHouse, приводит к немедленному созданию части хранения, содержащей данные из вставки вместе с другой метаинформацией, которая также необходимо сохранить. Поэтому отправка меньшего количества вставок, каждая из которых содержит больше данных, по сравнению с отправкой большего объема вставок, каждая из которых содержит меньше данных, уменьшит количество необходимых записей. Обычно мы рекомендуем вставлять данные в достаточно больших пакетах, как минимум 1,000 строк за раз, а в идеале от 10,000 до 100,000 строк. (Подробности здесь).
Если большие пакеты невозможны, используйте асинхронные вставки, описанные ниже.
Обеспечьте согласованные пакеты для идемпотентных повторных попыток
По умолчанию вставки в ClickHouse синхронные и идемпотентные (т.е. выполнение одной и той же вставки несколько раз имеет такой же эффект, как и выполнение ее один раз). Для таблиц семейства движка MergeTree ClickHouse по умолчанию автоматически удаляет дубликаты вставок.
Это означает, что вставки остаются устойчивыми в следующих случаях:
-
- Если узел, получающий данные, сталкивается с проблемами, запрос на вставку истекает (или выдает более конкретную ошибку) и не получает подтверждения.
-
- Если данные были записаны узлом, но подтверждение не может быть возвращено отправителю запроса из-за сетевых перебоев, отправитель либо получает тайм-аут, либо сетевую ошибку.
С точки зрения клиента (i) и (ii) могут быть трудно различимы. Однако в обоих случаях неподтвержденная вставка может быть немедленно повторена. Пока повторяемый запрос на вставку содержит те же данные в том же порядке, ClickHouse автоматически проигнорирует повторный запрос, если оригинальная вставка (неподтвержденная) прошла успешно.
Вставляйте в таблицу MergeTree или распределенную таблицу
Рекомендуем вставлять непосредственно в таблицу MergeTree (или Реплицированную таблицу), балансируя запросы по набору узлов, если данные шардированы, и устанавливая internal_replication=true. Это позволит ClickHouse реплицировать данные на доступные репликасные шард и обеспечивать окончательную согласованность данных.
Если эта балансировка нагрузки на клиентской стороне неудобна, то пользователи могут вставлять данные через распределенную таблицу, которая затем распределяет записи между узлами. Снова рекомендуется установить internal_replication=true. Однако следует отметить, что этот подход немного менее производителен, поскольку записи должны быть сделаны локально на узле с распределенной таблицей, а затем отправлены на шард.
Используйте асинхронные вставки для небольших пакетов
Существуют сценарии, когда пакетирование на стороне клиента нецелесообразно, например, в случае использования с наблюдаемыми системами с 100 или 1000 одноцелевых агентов, отправляющих логи, метрики, трассировки и т. д. В этом сценарии бесперебойная передача этих данных имеет ключевое значение для быстрого обнаружения проблем и аномалий. Более того, существует риск всплесков событий в наблюдаемых системах, что потенциально может вызвать большие всплески памяти и связанные с этим проблемы при попытке буферизации данных наблюдаемости на стороне клиента. Если большие пакеты не могут быть вставлены, пользователи могут делегировать пакетирование ClickHouse, используя асинхронные вставки.
С асинхронными вставками данные сначала вставляются в буфер, а затем записываются в хранилище базы данных позже в 3 этапа, как показано на диаграмме ниже:
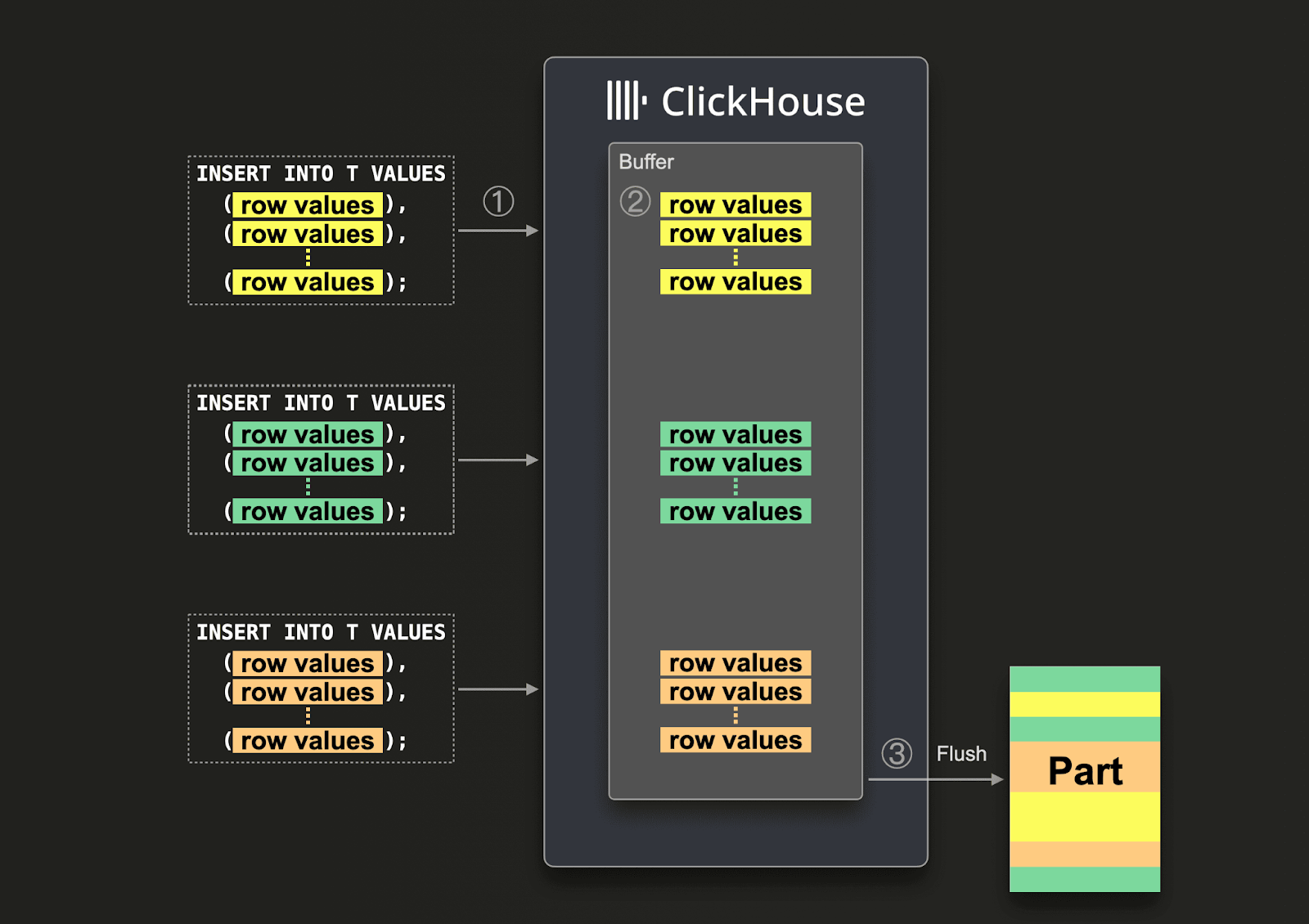
С включенными асинхронными вставками ClickHouse:
(1) получает запрос на вставку асинхронно.
(2) сначала записывает данные запроса в буфер в памяти.
(3) сортирует и записывает данные как часть в хранилище базы данных, только когда происходит следующий сброс буфера.
Перед сбросом буфера данные других асинхронных вставок из этого или других клиентов могут быть собраны в буфере. Часть, созданная из сброса буфера, будет потенциально содержать данные из нескольких асинхронных вставок. Обычно эта механика перемещает пакетирование данных с клиентской стороны на серверную сторону (инстанс ClickHouse).
Используйте официальные клиенты ClickHouse
ClickHouse имеет клиенты на самых популярных языках программирования. Эти клиенты оптимизированы для обеспечения корректного выполнения вставок и нативно поддерживают асинхронные вставки либо напрямую, как в Go клиенте, либо косвенно при включении на уровне запроса, пользователя или подключения.
Смотрите Клиенты и драйверы для полного списка доступных клиентов и драйверов ClickHouse.
Предпочитайте нативный формат
ClickHouse поддерживает множество входных форматов во время вставки (и запроса). Это значительное отличие от OLTP баз данных и делает загрузку данных из внешних источников значительно проще - особенно в сочетании с табличными функциями и возможностью загружать данные из файлов на диске. Эти форматы идеально подходят для загрузки данных ad hoc и задач по обработке данных.
Для приложений, стремящихся достичь оптимальной производительности вставки, пользователи должны вставлять данные, используя Нативный формат. Это поддерживается большинством клиентов (например, Go и Python) и гарантирует, что серверу придется выполнять минимальную работу, поскольку этот формат уже ориентирован на столбцы. Делая это, ответственность за преобразование данных в столбцовый формат лежит на стороне клиента. Это важно для эффективного масштабирования вставки.
В качестве альтернативы пользователи могут использовать RowBinary format (как используется Java клиентом), если предпочитается строковый формат - это обычно легче записать, чем Нативный формат. Этот способ более эффективен в терминах сжатия, сетевых накладных расходов и обработки на сервере, чем альтернативные строковые форматы, такие как JSON. Формат JSONEachRow может рассматриваться пользователями с более низкой производительностью записи, стремящимися к быстрой интеграции. Пользователи должны быть осведомлены о том, что данный формат приведет к повышенной нагрузке на CPU в ClickHouse из-за парсинга.
Используйте HTTP интерфейс
В отличие от многих традиционных баз данных, ClickHouse поддерживает HTTP интерфейс. Пользователи могут использовать это как для вставки, так и для запроса данных, используя любой из вышеуказанных форматов. Это часто предпочтительнее, чем нативный протокол ClickHouse, поскольку позволяет легко переключать трафик с помощью балансировщиков нагрузки. Мы ожидаем небольших различий в производительности вставки с нативным протоколом, который влечет за собой немного меньшие накладные расходы. Существующие клиенты используют один из этих протоколов (в некоторых случаях оба, например, Go клиент). Нативный протокол позволяет легко отслеживать прогресс запроса.
Смотрите HTTP интерфейс для получения дополнительных сведений.
Загрузка данных из Postgres
Для загрузки данных из Postgres пользователи могут использовать:
PeerDB by ClickHouse, инструмент ETL, специально разработанный для репликации баз данных PostgreSQL. Это доступно как в:- ClickHouse Cloud - доступно через наш новый коннектор (Частный предварительный просмотр) в ClickPipes, нашем управляемом сервисе загрузки данных. Заинтересованные пользователи могут зарегистрироваться здесь.
- Самоуправляемый - через open-source проект.
- PostgreSQL таблицу для чтения данных непосредственно, как показано в предыдущих примерах. Обычно подходит, если пакетная репликация на основе известного маркера времени, например, отметки времени, является достаточной или если это одноразовая миграция. Этот подход может масштабироваться до десятков миллионов строк. Пользователи, стремящиеся мигрировать более крупные наборы данных, должны рассмотреть возможность нескольких запросов, каждый из которых обрабатывает часть данных. Временные таблицы могут использоваться для каждого фрагмента перед тем, как его разделы будут перемещены в финальную таблицу. Это позволяет повторно пытаться выполнить неудачные запросы. Для получения дополнительных сведений о данной стратегии массовой загрузки смотрите здесь.
- Данные могут экспортироваться из PostgreSQL в формате CSV. Эти данные затем могут быть вставлены в ClickHouse из локальных файлов или через объектное хранилище с использованием табличных функций.
Если вам нужна помощь с вставкой больших наборов данных или вы сталкиваетесь с ошибками при импорте данных в ClickHouse Cloud, пожалуйста, свяжитесь с нами по адресу support@clickhouse.com, и мы сможем помочь.