Запись запросов в ClickHouse с использованием данных GitHub
Этот набор данных содержит все коммиты и изменения для репозитория ClickHouse. Его можно сгенерировать с помощью встроенного инструмента git-import, распространяемого с ClickHouse.
Сгенерированные данные предоставляют файл tsv для каждой из следующих таблиц:
commits- коммиты со статистикой.file_changes- файлы, измененные в каждом коммите, с информацией об изменениях и статистикой.line_changes- каждая измененная строка в каждом измененном файле в каждом коммите с полной информацией о строке и информации о предыдущем изменении этой строки.
На 8 ноября 2022 года каждый TSV имеет примерно следующий размер и количество строк:
commits- 7.8М - 266,051 строкfile_changes- 53М - 266,051 строкline_changes- 2.7Г - 7,535,157 строк
Генерация данных
Это необязательно. Мы свободно распространяем данные - смотрите Скачивание и вставка данных.
Это займет около 3 минут (на 8 ноября 2022 года на MacBook Pro 2021) для завершения для репозитория ClickHouse.
Полный список доступных опций можно получить из встроенной помощи инструмента.
Эта помощь также предоставляет DDL для каждой из вышеуказанных таблиц, например:
Эти запросы должны работать в любом репозитории. Не стесняйтесь исследовать и сообщать о своих находках. Некоторые рекомендации относительно времени выполнения (на ноябрь 2022 года):
- Linux -
~/clickhouse git-import- 160 минут
Скачивание и вставка данных
Следующие данные можно использовать для воспроизведения рабочей среды. Кроме того, этот набор данных доступен на play.clickhouse.com - см. Запросы для получения дополнительной информации.
Сгенерированные файлы для следующих репозиториев можно найти ниже:
- ClickHouse (8 ноября 2022 года)
- https://datasets-documentation.s3.amazonaws.com/github/commits/clickhouse/commits.tsv.xz - 2.5 МБ
- https://datasets-documentation.s3.amazonaws.com/github/commits/clickhouse/file_changes.tsv.xz - 4.5 МБ
- https://datasets-documentation.s3.amazonaws.com/github/commits/clickhouse/line_changes.tsv.xz - 127.4 МБ
- Linux (8 ноября 2022 года)
Для вставки этих данных подготовьте базу данных, выполнив следующие запросы:
Вставьте данные, используя INSERT INTO SELECT и функцию s3. Например, ниже мы вставляем файлы ClickHouse в каждую из их соответствующих таблиц:
commits
file_changes
line_changes
Запросы
Инструмент предлагает несколько запросов через свой вывод помощи. Мы ответили на них, а также на некоторые дополнительные интересные вопросы. Эти запросы имеют примерно возрастающую сложность по сравнению со случайным порядком инструмента.
Этот набор данных доступен на play.clickhouse.com в базах данных git_clickhouse. Мы предоставляем ссылку на эту среду для всех запросов, адаптируя имя базы данных по мере необходимости. Обратите внимание, что результаты в play могут отличаться от представленных здесь из-за различий во времени сбора данных.
История одного файла
Самый простой запрос. Здесь мы смотрим на все сообщения коммитов для StorageReplicatedMergeTree.cpp. Поскольку они, вероятно, более интересны, мы сортируем по самым недавним сообщениям в первую очередь.
Мы также можем просмотреть изменения строк, исключая переименования, т.е. мы не будем показывать изменения до события переименования, когда файл существовал под другим именем:
Обратите внимание, что существует более сложный вариант этого запроса, где мы находим историю коммитов по строкам файла, учитывая переименования.
Найти текущие активные файлы
Это важно для последующего анализа, когда мы хотим рассмотреть только текущие файлы в репозитории. Мы оцениваем этот набор как файлы, которые не были переименованы или удалены (а затем повторно добавлены/переименованы).
Обратите внимание, что, похоже, была повреждена история коммитов в отношении файлов в каталогах dbms, libs, tests/testflows/ во время их переименований. Поэтому мы также исключаем их.
Обратите внимание, что это позволяет файлам быть переименованными, а затем переименованными обратно в свои оригинальные значения. Сначала мы агрегируем old_path для списка файлов, удаленных в результате переименования. Мы объединяем это с последней операцией для каждого path. Наконец, мы фильтруем этот список, чтобы исключить те, где финальное событие не является Delete.
Обратите внимание, что мы пропустили импорт нескольких каталогов во время импорта, т.е.
--skip-paths 'generated\.cpp|^(contrib|docs?|website|libs/(libcityhash|liblz4|libdivide|libvectorclass|libdouble-conversion|libcpuid|libzstd|libfarmhash|libmetrohash|libpoco|libwidechar_width))/'
Применяя этот шаблон к git list-files, мы получаем 18155.
Наше текущее решение, таким образом, является оценкой текущих файлов.
Разница здесь вызвана несколькими факторами:
- Переименование может произойти одновременно с другими модификациями файла. Эти события перечислены как отдельные события в file_changes, но с одинаковым временем. Функция
argMaxне может их различать - она выбирает первое значение. Естественный порядок вставок (единственный способ узнать правильный порядок) не сохраняется при объединении, поэтому могут быть выбраны измененные события. Например, ниже файлsrc/Functions/geometryFromColumn.hимеет несколько модификаций перед тем, как быть переименованным вsrc/Functions/geometryConverters.h. Наше текущее решение может выбрать событиеModifyкак последнее изменение, что приводит к тому, чтоsrc/Functions/geometryFromColumn.hсохраняется.
- Поврежденная история коммитов - отсутствуют события удаления. Источник и причина TBD.
Эти различия не должны существенно повлиять на наш анализ. Мы приветствуем улучшенные версии этого запроса.
Список файлов с наибольшим количеством модификаций
Ограничивая текущими файлами, мы считаем количество модификаций как сумму удалений и добавлений.
В какой день недели обычно происходят коммиты?
Это имеет смысл с некоторым снижением продуктивности по пятницам. Здорово видеть, как люди коммитят код в выходные! Огромное спасибо нашим контрибьюторам!
История подкаталога/файла - количество строк, коммитов и контрибьюторов с течением времени
Это приведет к большим результатам запроса, которые невозможно показать или визуализировать, если они не отфильтрованы. Поэтому мы разрешаем фильтрацию файла или подкаталога в следующем примере. Здесь мы группируем по неделям, используя функцию toStartOfWeek - адаптируйте как необходимо.
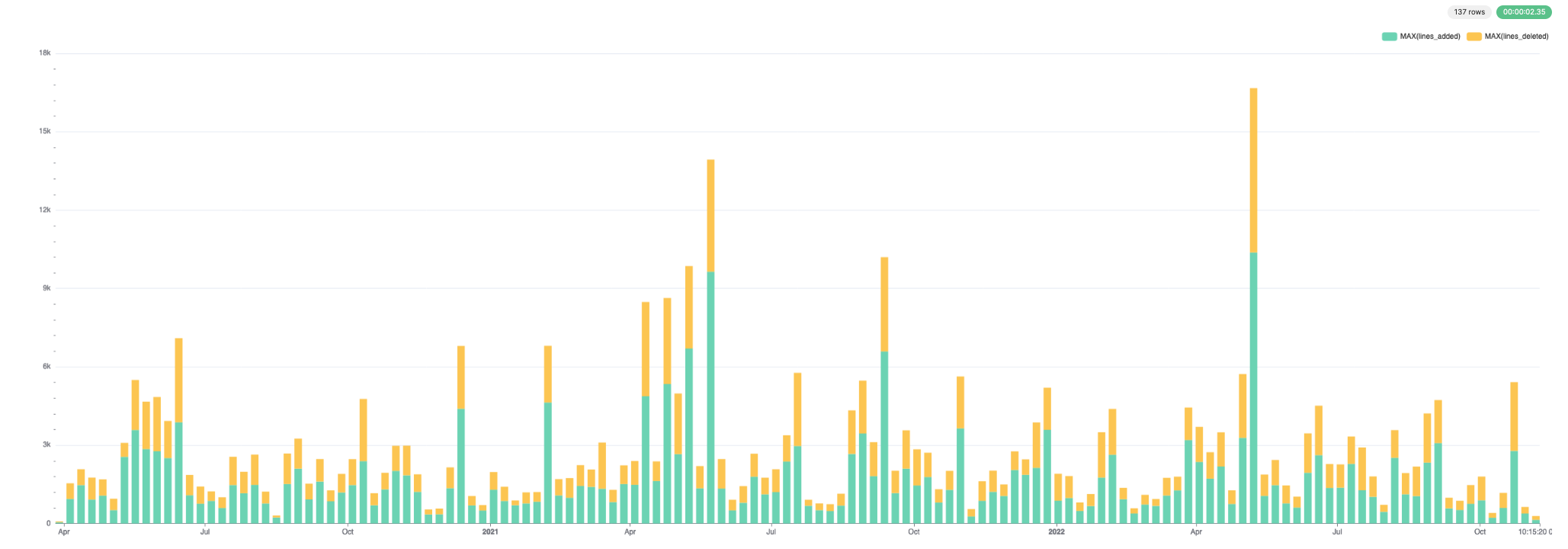
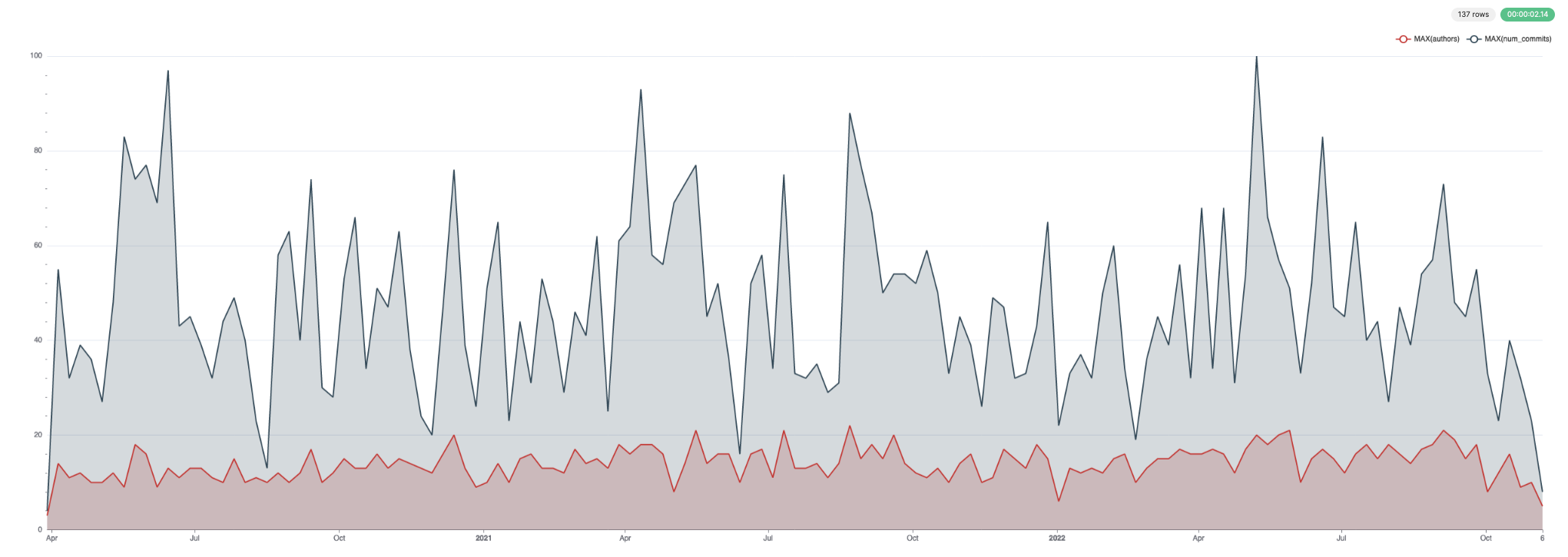
Эти данные хорошо визуализируются. Ниже мы используем Superset.
Для добавленных и удаленных строк:
Для коммитов и авторов:
Список файлов с максимальным количеством авторов
Ограничено только текущими файлами.
Самые старые строки кода в репозитории
Ограничено только текущими файлами.
Файлы с самой длинной историей
Ограничено только текущими файлами.
Наша основная структура данных, Merge Tree, очевидно, находится под постоянной эволюцией с долгой историей изменений!
Распределение участников в отношении документации и кода за месяц
Во время захвата данных изменения в папке docs/ были отфильтрованы из-за очень запятнанной истории коммитов. Результаты этого запроса, следовательно, не точны.
Пишем ли мы больше документации в определенные моменты месяца, например, вблизи дат выхода? Мы можем использовать функцию countIf, чтобы вычислить простое соотношение, визуализируя результат с использованием функции bar.
Может быть, немного больше ближе к концу месяца, но в целом мы поддерживаем хорошее равномерное распределение. Тем не менее, это недостоверно из-за фильтрации документации во время вставки данных.
Авторы с наибольшим распределением влияния
Мы рассматриваем разнообразие здесь как количество уникальных файлов, к которым автор внес вклад.
Посмотрим, у кого самые разнообразные коммиты в их недавней работе. Вместо ограничения по дате, мы ограничим последние N коммитов автора (в данном случае, мы использовали 3, но вы можете изменить):
Любимые файлы автора
Здесь мы выбираем нашего основателя Alexey Milovidov и ограничиваем наш анализ текущими файлами.
Это имеет смысл, поскольку Алексей отвечает за поддержку Change log. Но что если мы используем базовое имя файла, чтобы определить его популярные файлы - это позволяет учитывать переименования и должно сосредоточиться на вкладках кода.
Это, возможно, более точно отражает его области интересов.
Крупнейшие файлы с наименьшим количеством авторов
Для этого сначала нужно определить крупнейшие файлы. Оценка этого через полную реконструкцию файлов, для каждого файла, из истории коммитов будет очень дорогой!
Чтобы оценить, предположим, что мы ограничиваемся текущими файлами, мы суммируем добавления строк и вычитаем удаления. Затем мы можем вычислить соотношение длины к количеству авторов.
Текстовые словари, возможно, не являются реалистичными, поэтому давайте ограничим рекламу только кодом через фильтр по расширению файла!
В этом есть некоторый уклон в сторону актуальности - более новые файлы имеют меньше возможностей для коммитов. Что если мы ограничим файлы, которым минимум 1 год?
Распределение коммитов и строк кода по времени; по дням недели, по авторам; для конкретных подпапок
Мы интерпретируем это как количество строк, добавленных и удаленных по дням недели. В этом случае мы сосредотачиваемся на директории Functions
И по времени суток,
Это распределение имеет смысл, учитывая, что большая часть нашей команды разработки находится в Амстердаме. Функции bar помогают нам визуализировать эти распределения:
Матрица авторов, показывающая, какие авторы часто переписывают код других авторов
sign = -1 указывает на удаление кода. Мы исключаем знаки препинания и вставку пустых строк.
Диаграмма Санки (SuperSet) позволяет визуализировать это очень наглядно. Обратите внимание, что мы увеличиваем наш LIMIT BY до 3, чтобы получить 3 лучших удаляющих код для каждого автора, чтобы улучшить разнообразие в визуализации.
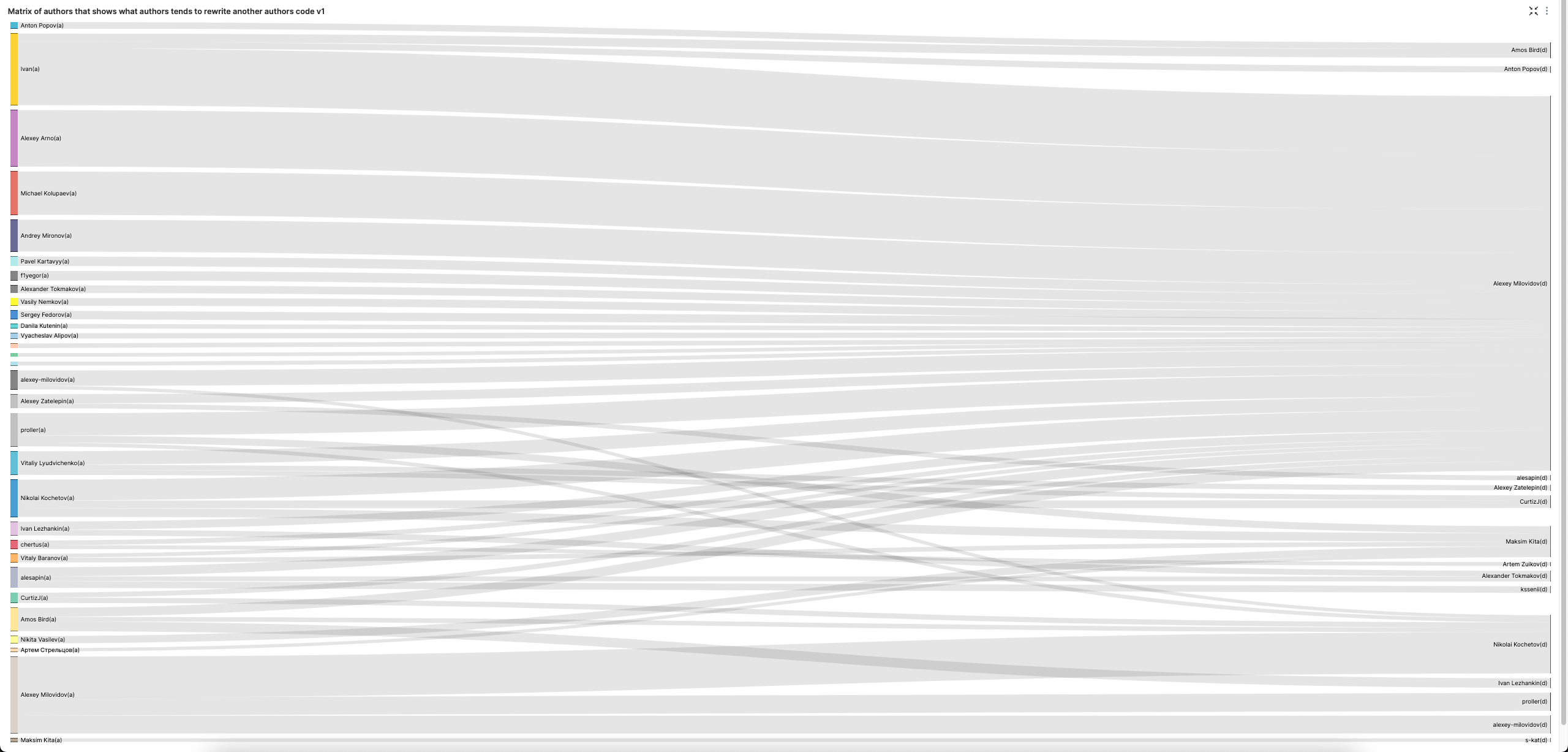
Алексей явно любит удалять код других. Давайте исключим его для более сбалансированного взгляда на удаление кода.

Кто является самым высоким процентным вкладчиком по дням недели?
Если мы рассмотрим всего по количеству коммитов:
Хорошо, здесь есть некоторые возможные преимущества у самого длительного автора - нашего основателя Алексея. Давайте ограничим наш анализ последним годом.
Это все еще немного просто и не отражает работу людей.
Лучший метрика может быть то, кто является ведущим вкладчиком каждый день в процентном соотношении к общему объему работ, выполненных за последний год. Обратите внимание, что мы рассматриваем удаление и добавление кода одинаково.
Распределение возраста кода по репозиторию
Мы ограничиваем анализ текущими файлами. Для краткости мы ограничиваем результаты глубиной 2 и 5 файлами на корневую папку. При необходимости скорректируйте.
Какой процент кода для автора был удален другими авторами?
Для этого вопроса нам нужно количество строк, написанных автором, разделенное на общее количество строк, которые были удалены другим вкладчиком.
Список файлов, которые были переписаны наибольшее количество раз
Самый простой подход к этому вопросу может заключаться в том, чтобы просто подсчитать наибольшее количество модификаций строк по пути (ограничиваясь текущими файлами), например:
Это не охватывает понятие "переписывания", однако, где большая часть файла изменяется в любом коммите. Для этого требуется более сложный запрос. Если мы считаем переписыванием, когда больше 50% файла удаляется и 50% добавляется. Вы можете настроить запрос в соответствии с вашим собственным пониманием того, что представляет собой такое переписывание.
Запрос ограничен только текущими файлами. Мы перечисляем все изменения файла, группируя по пути и хешу коммита, возвращая количество добавленных и удаленных строк. Используя оконную функцию, мы оцениваем общий размер файла в любой момент времени, выполняя кумулятивную сумму и оценивая влияние любого изменения на размер файла как строки, добавленные - строки, удаленные. Используя эту статистику, мы можем рассчитать процент файла, который был добавлен или удален для каждого изменения. Наконец, мы считаем количество изменений файла, которые составляют переписывание, т.е. (percent_add >= 0.5) AND (percent_delete >= 0.5) AND current_size > 50. Обратите внимание, что мы требуем, чтобы файлы имели более 50 строк, чтобы избежать ранних вкладов в файл, которые могли бы считаться переписыванием. Это также избегает предвзятости по отношению к очень маленьким файлам, которые могут быть более вероятно переписаны.
В какой день недели код имеет наибольшую вероятность оставаться в репозитории?
Для этого нам нужно уникально идентифицировать строку кода. Мы оцениваем это (так как одна и та же строка может появиться несколько раз в файле) по пути и содержимому строки.
Мы запрашиваем строки, добавленные, присоединяя это к удаленным строкам - фильтруя на случаи, когда последнее происходит позже первого. Это дает нам удаленные строки, из которых мы можем вычислить время между этими двумя событиями.
Наконец, мы агрегируем по этому набору данных, чтобы вычислить среднее количество дней, которые строки находятся в репозитории, по дням недели.
Файлы, отсортированные по среднему возрасту кода
Этот запрос использует тот же принцип, что и В какой день недели код имеет наибольшую вероятность оставаться в репозитории - стремясь уникально идентифицировать строку кода с помощью пути и содержимого строки. Это позволяет нам определить время между добавлением строки и её удалением. Однако мы фильтруем только текущие файлы и код, и усредняем время для каждого файла по строкам.
Кто склонен писать больше тестов / CPP кода / комментариев?
Есть несколько способов, как мы можем рассмотреть этот вопрос. Сосредоточив внимание на соотношении кода к тестам, этот запрос относительно прост - посчитать количество взносов в папки, содержащие tests, и вычислить соотношение к общему количеству взносов.
Обратите внимание, что мы ограничиваем пользователей более чем 20 изменениями, чтобы сосредоточиться на регулярных коммитерах и избежать предвзятости к разовым взносам.
Мы можем изобразить это распределение в виде гистограммы.
Большинство участников пишут больше кода, чем тестов, как и ожидалось.
Что насчет тех, кто добавляет больше всего комментариев при внесении кода?
Обратите внимание, что мы сортируем по взносам кода. Удивительно высокий процент для всех наших крупнейших участников и часть того, что делает наш код таким читаемым.
Как меняются коммиты авторов со временем по отношению к проценту кода/комментариев?
Для вычисления этого по автору тривиально,
Тем не менее, мы хотим увидеть, как это меняется в среднем по всем авторам с первого дня, когда они начали коммитить. Уменьшают ли они со временем количество комментариев, которые они пишут?
Чтобы вычислить это, мы сначала вычисляем соотношение комментариев для каждого автора со временем - аналогично Кто склонен писать больше тестов / CPP кода / комментариев?. Затем мы присоединяем это к дате начала каждого автора, позволяя нам рассчитать соотношение комментариев по неделям.
После вычисления среднего значения по неделям по всем авторам, мы выбираем эти результаты, выбирая каждую 10-ю неделю.
Воодушевляет то, что наш процент комментариев довольно постоянен и не ухудшается по мере того, как авторы продолжают вносить изменения.
Каково среднее время до переписывания кода и медиана (период полураспада кода)?
Мы можем использовать тот же принцип, что и Список файлов, которые переписывались наибольшее количество раз или большинством авторов, чтобы определить переписывания, но учитываем все файлы. Оконная функция используется для вычисления времени между переписываниями для каждого файла. Из этого мы можем вычислить среднее и медиану по всем файлам.
Когда наихудшее время для написания кода в том смысле, что код имеет наибольшую вероятность быть переписанным?
По аналогии с Каково среднее время до переписывания кода и медиана (период полураспада кода)? и Список файлов, которые переписывались наибольшее количество раз или большинством авторов, мы агрегируем по дню недели. Скорректируйте по мере необходимости, например, по месяцу года.
Код каких авторов наименее подвержен изменениям?
Мы определяем "липкий" как то, насколько долго код автора остается прежним, прежде чем его переписывают. Аналогично предыдущему вопросу Каково среднее время до переписывания кода и медиана (период полураспада кода)? - используя тот же критерий для переписываний, т.е. 50% добавлений и 50% удалений из файла. Мы вычисляем среднее время переписывания по авторам и учитываем только тех авторов, которые внесли изменения в более чем два файла.
Наибольшее количество подряд идущих дней коммитов автором
Этот запрос сначала требует от нас рассчитать дни, когда автор сделал коммиты. Используя оконную функцию, разбивая по авторам, мы можем вычислить дни между их коммитами. Для каждого коммита, если время с последнего коммита составляет 1 день, мы помечаем его как последовательное (1), а в противном случае - 0, сохраняя этот результат в consecutive_day.
Наши последующие массивные функции вычисляют самую длинную последовательность последовательных единиц для каждого автора. Сначала используется функция groupArray, чтобы собрать все значения consecutive_day для автора. Этот массив из единиц и нулей затем разбивается по значениям 0 на подсмемейки. Наконец, мы вычисляем самую длинную подсмейку.
История коммитов файла построчно
Файлы могут быть переименованы. Когда это происходит, мы получаем событие переименования, где столбец path установлен на новый путь файла, а old_path представляет собой предыдущее местоположение, например:
Это затрудняет просмотр всей истории файла, так как у нас нет единого значения, соединяющего все изменения строк или файлов.
Чтобы решить эту проблему, мы можем использовать пользовательские функции (UDF). В настоящее время они не могут быть рекурсивными, поэтому, чтобы определить историю файла, мы должны определить серию UDF, которые вызывают друг друга явно.
Это означает, что мы можем отслеживать переименования только до максимальной глубины - в приведенном ниже примере это 5 уровней. Маловероятно, что файл будет переименован больше раз, чем это, поэтому на данный момент этого достаточно.
Вызывая file_path_history('src/Storages/StorageReplicatedMergeTree.cpp'), мы рекурсивно проходим через историю переименований, причем каждая функция вызывает следующий уровень с old_path. Результаты объединяются с помощью arrayConcat.
Например,
Мы можем использовать эту возможность, чтобы собрать коммиты для всей истории файла. В этом примере мы показываем один коммит для каждого из значений path.
Нерешенные вопросы
Git blame
Это особенно трудно получить точный результат из-за неспособности в настоящее время сохранять состояние в массивных функциях. Это станет возможным с arrayFold или arrayReduce, которые позволяют удерживать состояние на каждой итерации.
Приблизительное решение, достаточное для высокоуровневого анализа, может выглядеть следующим образом:
Мы приветствуем точные и улучшенные решения здесь.