Словарь
Словарь в ClickHouse предоставляет представление данных в оперативной памяти в формате ключ-значение из различных внутренних и внешних источников, оптимизируя для супернизкой задержки запросов на поиск.
Словари полезны для:
- Улучшения производительности запросов, особенно при использовании с
JOINами - Обогащения принимаемых данных на лету без замедления процесса загрузки
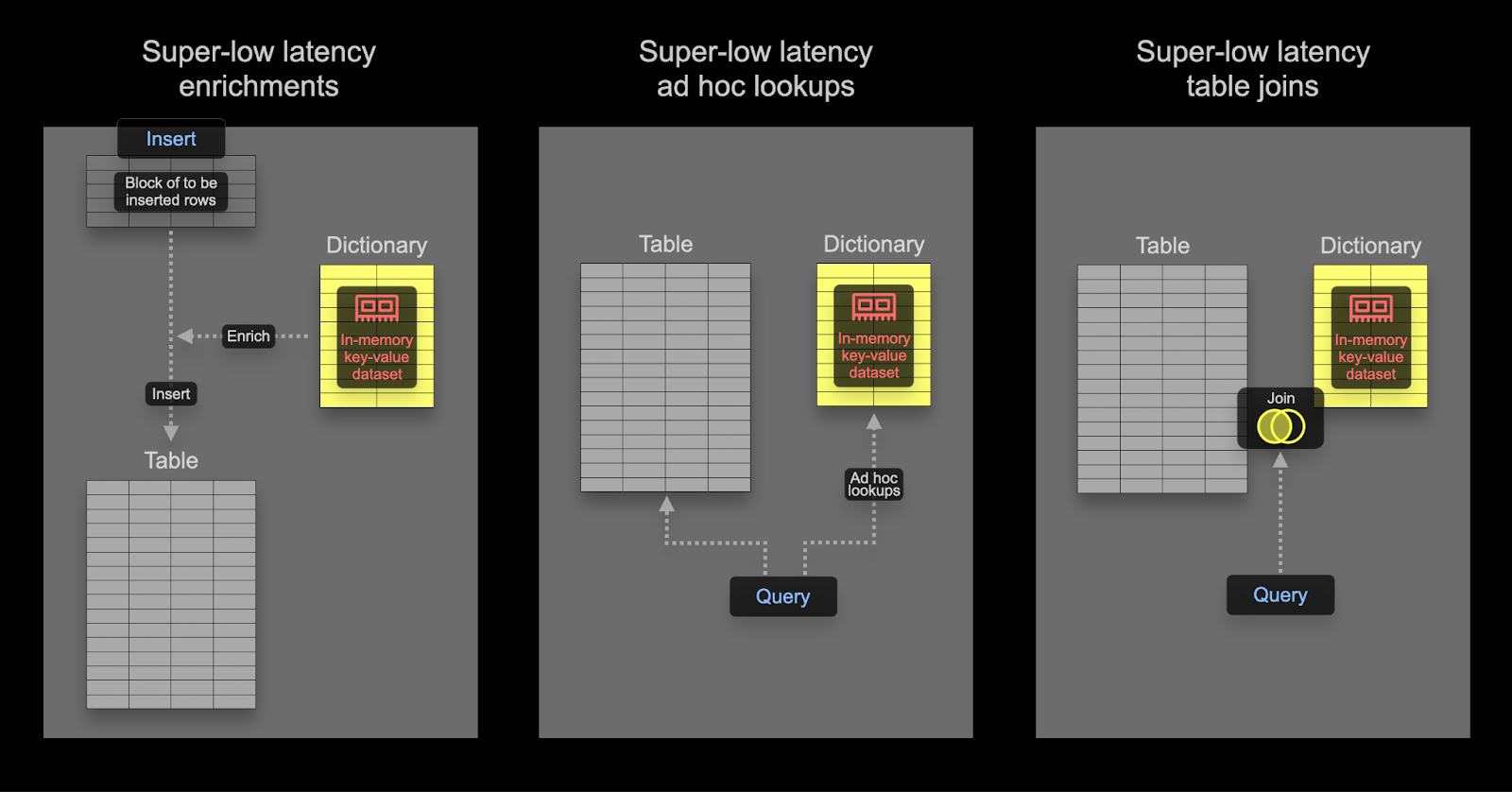
Ускорение соединений с использованием словаря
Словари могут использоваться для ускорения определенного типа JOIN: LEFT ANY типа, когда ключ соединения должен соответствовать ключевому атрибуту подлежащего хранилища ключ-значение.
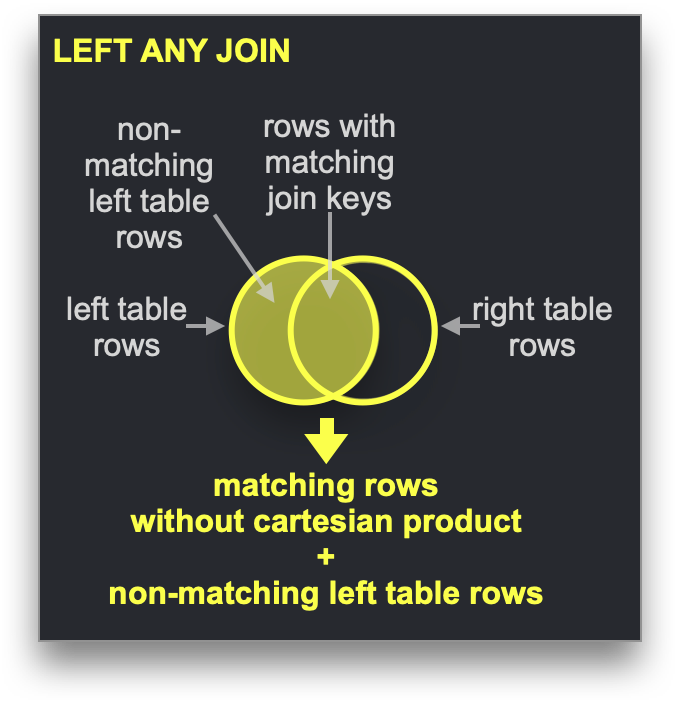
Если это так, ClickHouse может использовать словарь для выполнения Прямого соединения. Это самый быстрый алгоритм соединения в ClickHouse и применяется, когда подлежащий движок таблицы для правосторонней таблицы поддерживает запросы ключ-значение с низкой задержкой. В ClickHouse есть три движка таблиц, предоставляющих это: Join (который по сути является предрассчитанной хеш-таблицей), EmbeddedRocksDB и Dictionary. Мы опишем подход, основанный на словаре, но механика будет одинаковой для всех трех движков.
Алгоритм прямого соединения требует, чтобы правая таблица была поддержана словарем, так что данные для соединения из этой таблицы уже присутствуют в памяти в виде структуры данных ключ-значение с низкой задержкой.
Пример
Используя набор данных Stack Overflow, давайте ответим на вопрос: Какой самый спорный пост о SQL на Hacker News?
Мы определим спорный пост как такой, у которого аналогичное количество положительных и отрицательных голосов. Мы вычислим это абсолютное различие, где значение, близкое к 0, означает большее количество споров. Мы предположим, что пост должен иметь как минимум 10 положительных и отрицательных голосов - посты, за которые никто не голосует, не являются спорами.
С нашими данными, нормализованными, этот запрос в настоящее время требует JOIN с использованием таблиц posts и votes:
Используйте меньшие наборы данных на правой стороне
JOIN: Этот запрос может показаться более многословным, чем необходимо, поскольку фильтрация поPostIdпроисходит как в внешнем, так и подзапросах. Это оптимизация производительности, которая обеспечивает быстрый ответ на запрос. Для оптимальной производительности всегда убедитесь, что на правой сторонеJOINнаходится меньший набор данных и он как можно меньше. Для получения советов по оптимизации производительностиJOINи понимания доступных алгоритмов, мы рекомендуем эту серию блогов.
Хотя этот запрос и быстрый, он зависит от того, чтобы мы аккуратно написали JOIN, чтобы добиться хорошей производительности. В идеале, мы бы просто отфильтровали посты до тех, что содержат "SQL", прежде чем смотреть на количество UpVote и DownVote для поднабора блогов, чтобы вычислить нашу метрику.
Применение словаря
Чтобы продемонстрировать эти концепции, мы используем словарь для наших данных голосования. Поскольку словари обычно хранятся в памяти (ssd_cache является исключением), пользователи должны учитывать размер данных. Подтверждая размер нашей таблицы votes:
Данные будут храниться в разжатом виде в нашем словаре, поэтому нам нужно как минимум 4 ГБ памяти, если мы собираемся хранить все столбцы (мы этого не сделаем) в словаре. Словарь будет реплицирован по нашему кластеру, поэтому это количество памяти необходимо зарезервировать на каждый узел.
В приведенном ниже примере данные для нашего словаря поступают из таблицы ClickHouse. Хотя это представляет собой наиболее распространенный источник словарей, поддерживается ряд источников, включая файлы, http и базы данных, включая Postgres. Как мы покажем, словари могут быть автоматически обновлены, что является идеальным способом гарантировать, что маленькие наборы данных, подлежащие частым изменениям, доступны для прямых соединений.
Нашему словарю нужен первичный ключ, по которому будут выполняться запросы. Это концептуально идентично первичному ключу транзакционной базы данных и должно быть уникальным. Наш запрос требует поиска по ключу соединения - PostId. Словарь, в свою очередь, должен быть заполнен общим количеством положительных и отрицательных голосов на каждый PostId из нашей таблицы votes. Вот запрос для получения этих данных словаря:
Для создания нашего словаря требуется следующий DDL - обратите внимание на использование нашего вышеуказанного запроса:
В самоуправляемом OSS вышеуказанную команду необходимо выполнить на всех узлах. В ClickHouse Cloud словарь будет автоматически реплицирован на все узлы. Вышеуказанная команда была выполнена на узле ClickHouse Cloud с 64 ГБ RAM, затратив 36 секунд на загрузку.
Чтобы подтвердить использование памяти нашим словарем:
Теперь извлечение положительных и отрицательных голосов для конкретного PostId можно выполнить с помощью простой функции dictGet. Ниже мы получаем значения для поста 11227902:
Не только этот запрос гораздо проще, но он также более чем в два раза быстрее! Это можно оптимизировать дальше, загрузив в словарь только посты с более чем 10 положительными и отрицательными голосами и сохранив только предварительно вычисленное значение спора.
Обогащение данных во время запроса
Словари могут использоваться для поиска значений во время выполнения запроса. Эти значения могут возвращаться в результатах или использоваться в агрегациях. Предположим, мы создаем словарь для сопоставления идентификаторов пользователей с их местоположением:
Мы можем использовать этот словарь для обогащения результатов постов:
Похожие на наш вышеуказанный пример с соединением, мы можем использовать тот же словарь, чтобы эффективно определить, откуда происходит наибольшее количество постов:
Обогащение данных во время индексации
В приведенном выше примере мы использовали словарь во время выполнения запроса, чтобы исключить соединение. Словари также могут использоваться для обогащения строк во время вставки. Это обычно уместно, если значение обогащения не изменяется и существует во внешнем источнике, который можно использовать для заполнения словаря. В этом случае обогащение строки во время вставки позволяет избежать поиска значений в словаре во время выполнения запроса.
Предположим, что Location пользователя в Stack Overflow никогда не меняется (на самом деле они меняются) - конкретно, столбец Location таблицы users. Предположим, мы хотим делать аналитический запрос по таблице постов по местоположению. Это содержит UserId.
Словарь предоставляет сопоставление от идентификатора пользователя к местоположению, основанное на таблице users:
Мы исключаем пользователей с
Id < 0, что позволяет нам использовать тип словаряHashed. Пользователи сId < 0являются системными пользователями.
Чтобы воспользоваться этим словарем во время вставки в таблицу постов, нам нужно изменить схему:
В приведенном выше примере столбец Location объявлен как MATERIALIZED. Это означает, что значение может быть предоставлено как часть запроса INSERT и будет всегда вычисляться.
ClickHouse также поддерживает
DEFAULTстолбцы (где значение может быть вставлено или вычислено, если не предоставлено).
Чтобы заполнить таблицу, мы можем использовать обычный INSERT INTO SELECT из S3:
Теперь мы можем получить имя местоположения, откуда происходит наибольшее количество постов:
Расширенные темы словарей
Выбор LAYOUT словаря
Клаузула LAYOUT управляет внутренней структурой данных для словаря. Существуют различные варианты, и они задокументированы здесь. Некоторые советы по выбору правильного макета можно найти здесь.
Обновление словарей
Мы указали LIFETIME для словаря как MIN 600 MAX 900. LIFETIME - это интервал обновления для словаря, с приведенными здесь значениями, что обеспечивает периодическую перезагрузку в случайном интервале от 600 до 900 секунд. Этот случайный интервал необходим для распределения нагрузки на источник словаря при обновлении на большом количестве серверов. Во время обновлений старая версия словаря все еще может запрашиваться, только начальная загрузка блокирует запросы. Обратите внимание, что установка (LIFETIME(0)) предотвращает обновление словарей. Словари могут быть принудительно перезагружены с помощью команды SYSTEM RELOAD DICTIONARY.
Для источников базы данных, таких как ClickHouse и Postgres, вы можете настроить запрос, который будет обновлять словари только в том случае, если они действительно изменились (ответ на запрос определяет это), а не по периодическому интервалу. Дополнительные детали можно найти здесь.
Другие типы словарей
ClickHouse также поддерживает Иерархические, Полигональные и словари регулярных выражений.