Проектирование схемы
Понимание эффективного проектирования схемы является ключом к оптимизации производительности ClickHouse и включает в себя выбор, который часто связан с компромиссами, при этом оптимальный подход зависит от обрабатываемых запросов, а также от таких факторов, как частота обновления данных, требования к задержке и объем данных. Этот гид предоставляет обзор лучших практик проектирования схем и техник моделирования данных для оптимизации производительности ClickHouse.
Набор данных Stack Overflow
Для примеров в этом руководстве мы используем подмножество набора данных Stack Overflow. Это содержит каждый пост, голос, пользователя, комментарий и значок, которые имели место на Stack Overflow с 2008 года по апрель 2024 года. Эти данные доступны в формате Parquet, используя схемы ниже, в S3 ведре s3://datasets-documentation/stackoverflow/parquet/:
Основные ключи и связи, указанные здесь, не обеспечиваются через ограничения (Parquet является файловым форматом, а не форматом таблицы) и просто указывают на то, как данные связаны и какие уникальные ключи они имеют.
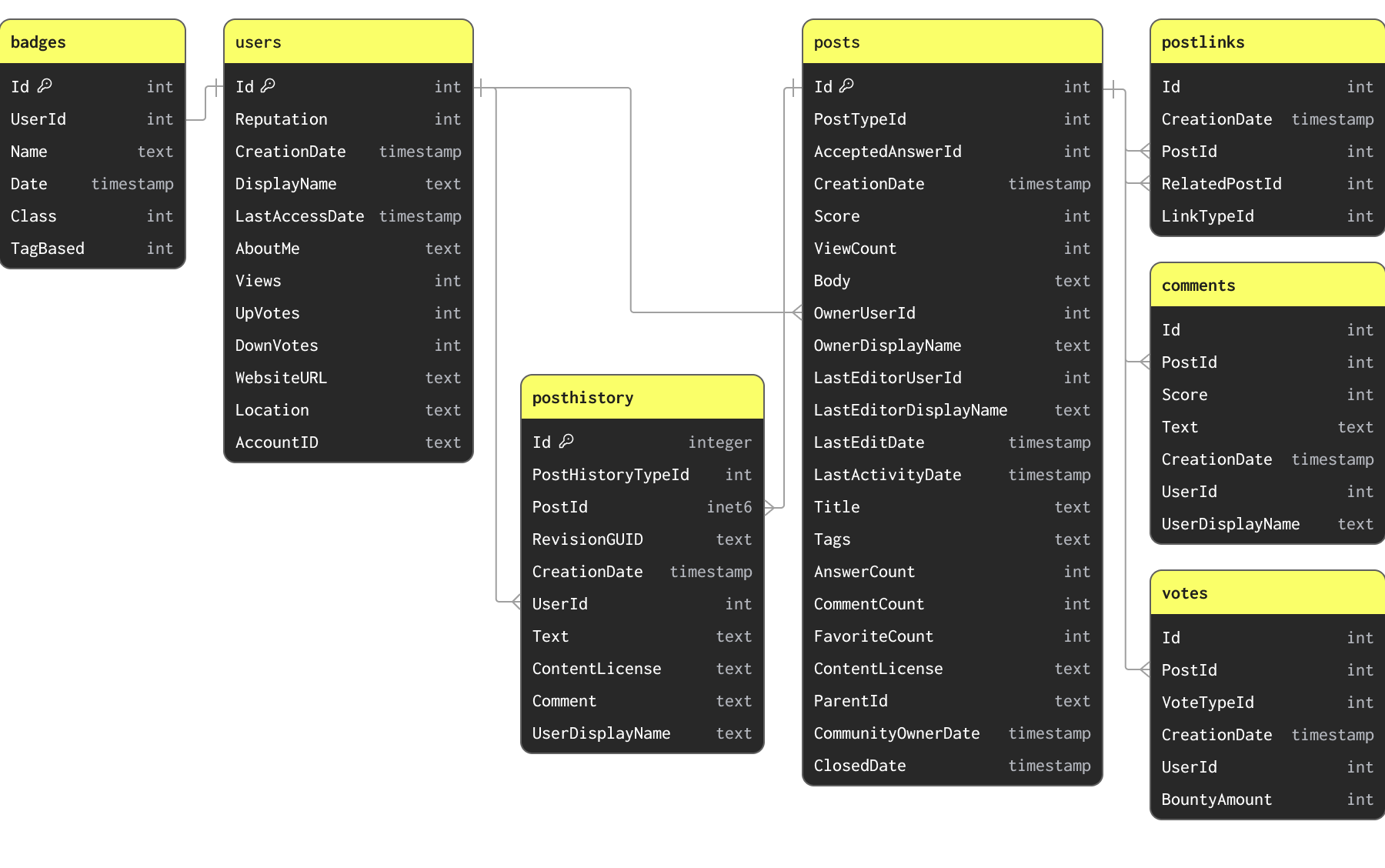
Набор данных Stack Overflow содержит несколько связанных таблиц. В любой задаче моделирования данных мы рекомендуем пользователям сосредоточиться на загрузке своей основной таблицы в первую очередь. Это может быть не обязательно самая большая таблица, но та, на основе которой вы ожидаете большинство аналитических запросов. Это позволит вам ознакомиться с основными концепциями и типами ClickHouse, что особенно важно, если вы переходите с преимущественно OLTP фоновой системы. Эта таблица может потребовать переоформления, так как будут добавляться дополнительные таблицы для полной эксплуатации возможностей ClickHouse и получения оптимальной производительности.
Вышеуказанная схема намеренно не является оптимальной для целей этого руководства.
Установите начальную схему
Поскольку таблица posts будет целевой для большинства аналитических запросов, мы сосредотачиваемся на установлении схемы для этой таблицы. Эти данные доступны в публичном S3 ведре s3://datasets-documentation/stackoverflow/parquet/posts/*.parquet с файлом на каждый год.
Загрузка данных из S3 в формате Parquet представляет собой наиболее распространенный и предпочтительный способ загрузки данных в ClickHouse. ClickHouse оптимизирован для обработки Parquet и может потенциально читать и вставлять десятки миллионов строк из S3 в секунду.
ClickHouse предоставляет возможность вывода схемы для автоматического определения типов для набора данных. Это поддерживается для всех форматов данных, включая Parquet. Мы можем использовать эту функцию для определения типов ClickHouse для данных через функцию таблицы s3 и команду DESCRIBE. Обратите внимание, что мы используем шаблон glob *.parquet, чтобы прочитать все файлы в папке stackoverflow/parquet/posts.
Функция s3 table function позволяет запрашивать данные в S3 непосредственно в ClickHouse. Эта функция совместима со всеми файловыми форматами, которые поддерживает ClickHouse.
Это предоставляет нам начальную не оптимизированную схему. По умолчанию ClickHouse сопоставляет их с эквивалентными Nullable типами. Мы можем создать таблицу ClickHouse, используя эти типы с помощью простой команды CREATE EMPTY AS SELECT.
Несколько важных моментов:
Наша таблица posts пуста после выполнения этой команды. Данные не были загружены. Мы указали MergeTree в качестве нашего механизма таблицы. MergeTree - это наиболее распространенный механизм таблицы ClickHouse, который вы, вероятно, будете использовать. Это многофункциональный инструмент в вашем арсенале ClickHouse, способный обрабатывать PB данных и обслуживать большинство аналитических случаев. Существуют и другие механизмы таблиц для случаев использования, таких как CDC, которые должны поддерживать эффективные обновления.
Клаузула ORDER BY () означает, что у нас нет индекса и, более конкретно, нет порядка в наших данных. Об этом позже. На данный момент просто знайте, что все запросы потребуют линейного сканирования.
Чтобы подтвердить, что таблица была создана:
С нашей начальной схемой определенной, мы можем заполнить данные, используя INSERT INTO SELECT, читая данные с помощью функции таблицы s3. Следующий запрос загружает данные posts примерно за 2 минуты на облачном экземпляре ClickHouse с 8 ядрами.
Вышеуказанный запрос загружает 60 миллионов строк. Хотя это небольшое количество для ClickHouse, пользователи с медленными интернет-соединениями могут захотеть загрузить подмножество данных. Это можно сделать, просто указав годы, которые они хотят загрузить, через шаблон glob, например:
https://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/2008.parquetилиhttps://datasets-documentation.s3.eu-west-3.amazonaws.com/stackoverflow/parquet/posts/{2008, 2009}.parquet. Смотрите здесь, как можно использовать шаблоны glob для выбора подмножеств файлов.
Оптимизация типов
Одним из секретов производительности запросов ClickHouse является сжатие.
Меньше данных на диске означает меньше I/O и, следовательно, более быстрые запросы и вставки. Нагрузка от любого алгоритма сжатия в отношении CPU в большинстве случаев будет компенсирована сокращением ввода-вывода. Поэтому улучшение сжатия данных должно быть первым приоритетом при обеспечении быстроты запросов ClickHouse.
Почему ClickHouse так хорошо сжимает данные, мы рекомендуем этот артикул. В кратком изложении, будучи столбцовой базой данных, значения будут записываться в порядке столбцов. Если эти значения отсортированы, одни и те же значения будут соседствовать друг с другом. Алгоритмы сжатия эксплуатируют смежные паттерны данных. Кроме того, ClickHouse имеет кодеки и гранулярные типы данных, которые позволяют пользователям дополнительно настраивать техники сжатия.
Сжатие в ClickHouse будет зависеть от 3 основных факторов: ключа сортировки, типов данных и любых используемых кодеков. Все они настраиваются через схему.
Наибольшее начальное улучшение в сжатии и производительности запроса можно получить за счет простого процесса оптимизации типов. Можно применить несколько простых правил для оптимизации схемы:
- Используйте строгие типы - Наша начальная схема использовала строки для многих столбцов, которые явно являются числовыми. Использование правильных типов гарантирует ожидаемую семантику при фильтрации и агрегации. То же самое касается типов даты, которые были правильно указаны в файлах Parquet.
- Избегайте Nullable столбцов - По умолчанию предполагалось, что вышеупомянутые столбцы могут быть Null. Тип Nullable позволяет запросам различать пустое и Null значение. Это создает отдельный столбец типа UInt8. Этот дополнительный столбец необходимо обрабатывать каждый раз, когда пользователь работает с nullable столбцом. Это приводит к дополнительному использованию пространства хранения и почти всегда отрицательно сказывается на производительности запросов. Используйте Nullable только если есть разница между значением по умолчанию пустого значения для типа и Null. Например, значение 0 для пустых значений в столбце
ViewCountбудет достаточно для большинства запросов и не повлияет на результаты. Если пустые значения следует обрабатывать иначе, их также можно исключить из запросов с помощью фильтра. - Используйте минимальную точность для числовых типов - ClickHouse имеет ряд числовых типов, предназначенных для различных диапазонов чисел и точности. Всегда старайтесь минимизировать количество бит, используемых для представления столбца. Кроме целочисленных типов разного размера, например, Int16, ClickHouse предлагает беззнаковые варианты, минимальное значение которых равно 0. Эти типы могут позволить использовать меньше бит для столбца, например, UInt16 имеет максимальное значение 65535, вдвое больше, чем Int16. Предпочитайте эти типы, когда это возможно, вместо более крупных знаковых вариантов.
- Минимальная точность для типов даты - ClickHouse поддерживает несколько типов даты и даты/времени. Date и Date32 могут использоваться для хранения чистых дат, причем последний поддерживает более широкий диапазон дат за счет большего числа бит. DateTime и DateTime64 обеспечивают поддержку дат и времени. DateTime ограничен секундной гранулярностью и использует 32 бита. DateTime64, как следует из названия, использует 64 бита, но обеспечивает поддержку гранулярности до наносекунд. Как всегда, выбирайте более грубую версию, подходящую для запросов, минимизируя количество бит, необходимых.
- Используйте LowCardinality - Числа, строки, столбцы даты или даты/времени с небольшим количеством уникальных значений могут быть закодированы с помощью типа LowCardinality. Этот словарь кодирует значения, уменьшая размер на диске. Рассмотрите этот вариант для столбцов с менее чем 10 тыс. уникальных значений.
- FixedString для специальных случаев - Строки, которые имеют фиксированную длину, могут быть закодированы с помощью типа FixedString, например, коды языков и валют. Это эффективно, когда данные имеют длину ровно N байт. В остальных случаях это, вероятно, уменьшит эффективность, и предпочтение следует отдавать LowCardinality.
- Enums для проверки данных - Тип Enum может быть использован для эффективной кодировки перечисленных типов. Enums могут быть 8 или 16 бит, в зависимости от количества уникальных значений, которые они должны содержать. Рассмотрите использование этого, если вам нужна проверка при вставке (необъявленные значения будут отклонены) или если вы хотите выполнить запросы, которые используют естественный порядок в значениях Enum, например, представьте себе столбец отзывов, содержащий ответы пользователей
Enum(':(' = 1, ':|' = 2, ':)' = 3).
Подсказка: Чтобы узнать диапазон всех столбцов и количество уникальных значений, пользователи могут использовать простой запрос
SELECT * APPLY min, * APPLY max, * APPLY uniq FROM table FORMAT Vertical. Мы рекомендуем выполнять это для меньшего подмножества данных, поскольку это может быть дорого. Этот запрос требует, чтобы числовые значения были как минимум определены как таковые для получения точного результата, т.е. не как строка.
Применяя эти простые правила к нашей таблице posts, мы можем определить оптимальный тип для каждого столбца:
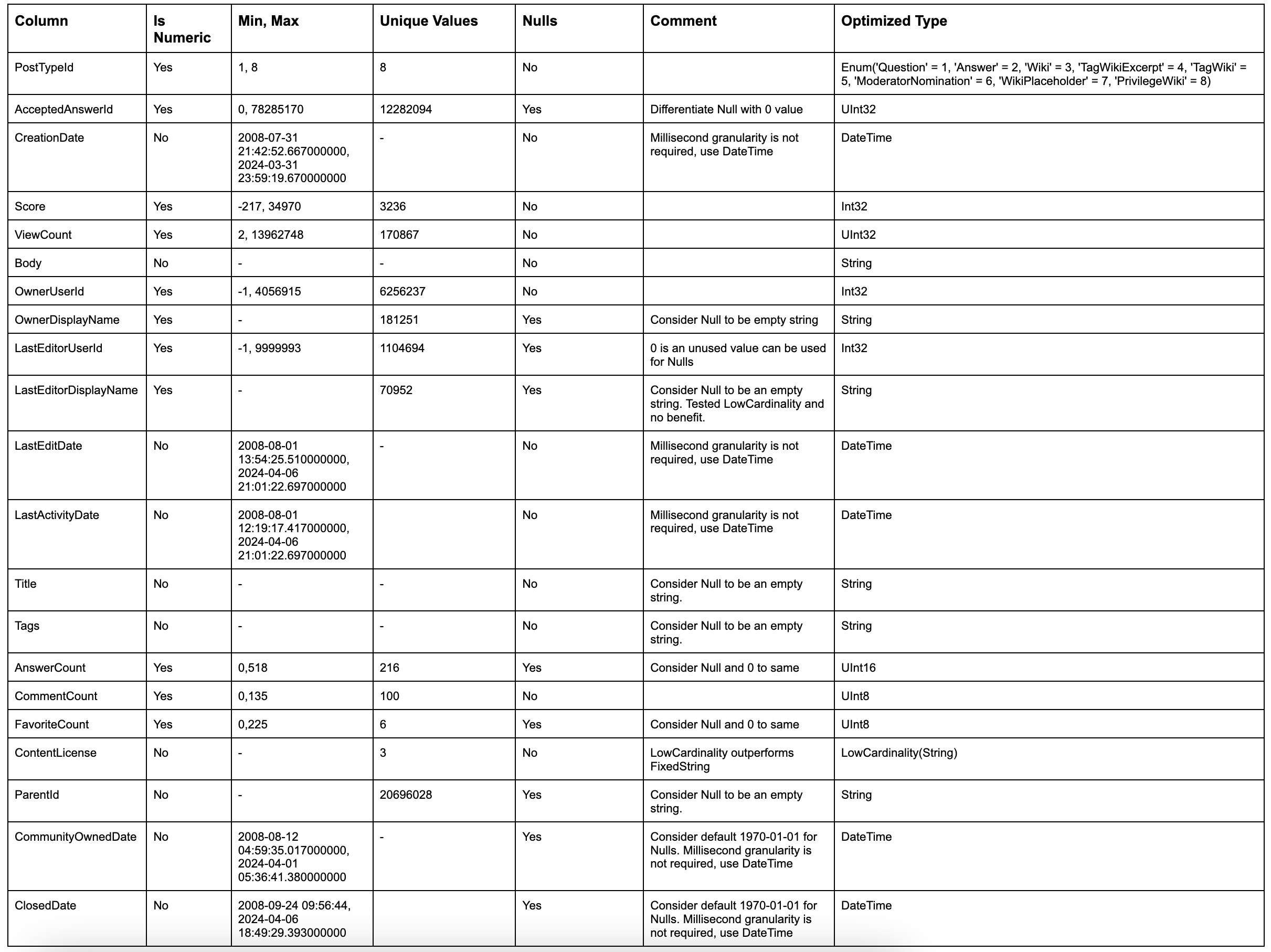
Вышеуказанное дает нам следующую схему:
Мы можем заполнить это с помощью простого INSERT INTO SELECT, читая данные из нашей предыдущей таблицы и вставляя в эту:
Мы не сохраняем никаких null значений в нашей новой схеме. Вышеуказанная вставка автоматически конвертирует их в значения по умолчанию для их соответствующих типов - 0 для целых чисел и пустое значение для строк. ClickHouse также автоматически преобразует любые числовые значения в их целевую точность. Основные (Сортировочные) ключи в ClickHouse Пользователи, приходящие из OLTP баз данных, часто ищут эквивалентное понятие в ClickHouse.
Выбор сортировочного ключа
На тех масштабах, на которых часто используется ClickHouse, эффективность использования памяти и диска имеет первостепенное значение. Данные записываются в таблицы ClickHouse партиями, известными как части, с правилами, применяемыми для объединения этих частей в фоновом режиме. В ClickHouse каждая часть имеет свой собственный первичный индекс. Когда части объединяются, также объединяются первичные индексы объединенной части. Первичный индекс части имеет одну запись индекса на группу строк - эта техника называется разреженным индексированием.
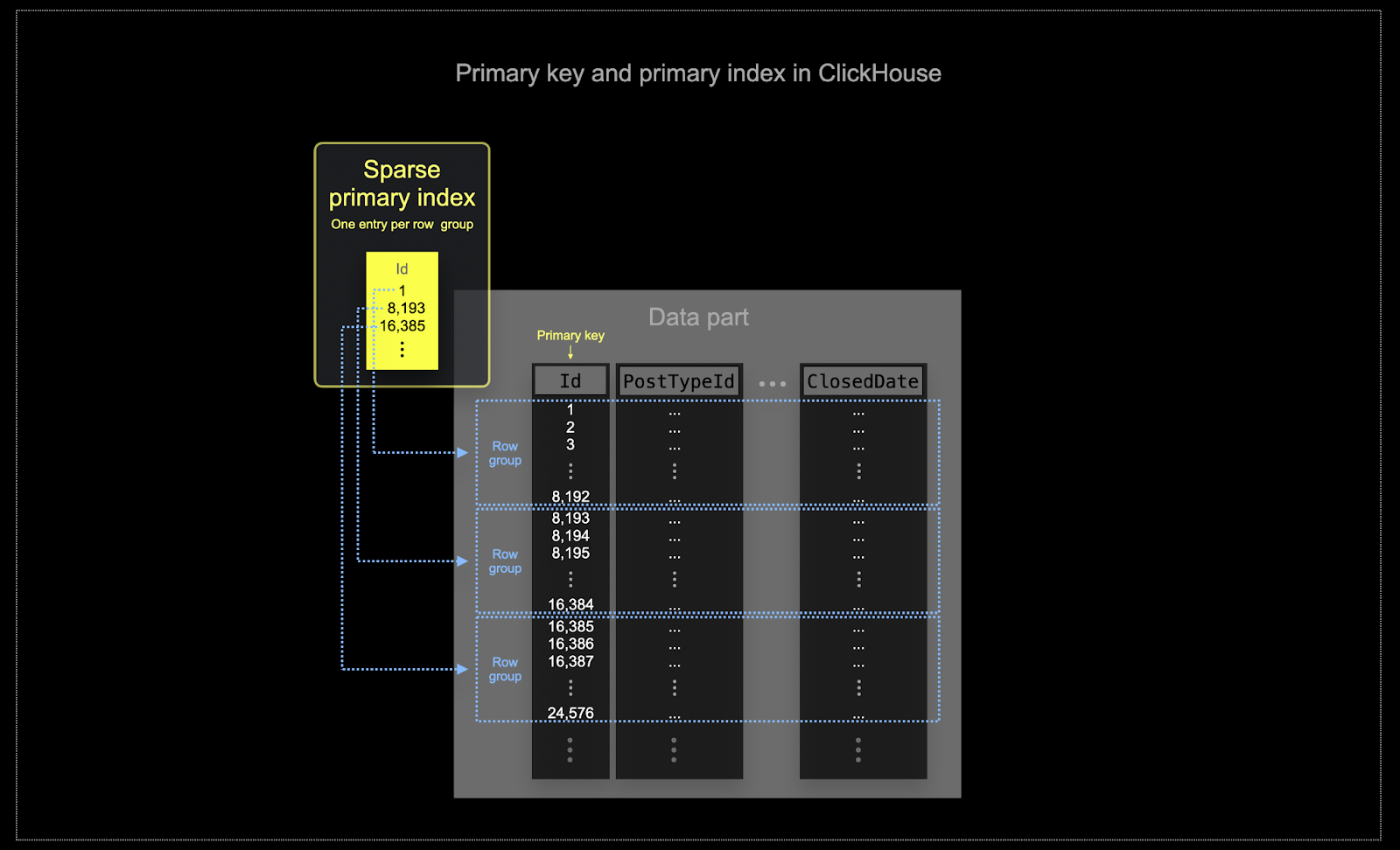
Выбранный ключ в ClickHouse определит не только индекс, но и порядок, в котором данные записываются на диск. Из-за этого он может драматически повлиять на уровни сжатия, что, в свою очередь, может повлиять на производительность запросов. Сортировочный ключ, который приводит к тому, что значения большинства столбцов записываются в смежном порядке, позволит выбранному алгоритму сжатия (и кодекам) более эффективно сжимать данные.
Все столбцы в таблице будут отсортированы на основе значений указанного сортировочного ключа, независимо от того, включены ли они в сам ключ. Например, если
CreationDateиспользуется в качестве ключа, порядок значений во всех остальных столбцах будет соответствовать порядку значений в столбцеCreationDate. Можно указать несколько сортировочных ключей - это будет сортироваться с той же семантикой, что и клаузулаORDER BYв запросеSELECT.
Некоторые простые правила могут быть применены для помощи в выборе сортировочного ключа. Следующие правила могут иногда конфликтовать, поэтому рассматривайте их в указанном порядке. Пользователи могут идентифицировать несколько ключей в этом процессе, 4-5 обычно бывает достаточно:
- Выбирайте столбцы, которые соответствуют вашим обычным фильтрам. Если столбец часто используется в условиях
WHERE, приоритизируйте включение этих столбцов в ваш ключ выше тех, которые используются реже. Предпочитайте столбцы, которые помогают исключить большой процент от общего количества строк при фильтрации, тем самым уменьшая объем данных, которые необходимо прочитать. - Предпочитайте столбцы, которые, вероятно, будут тесно связаны с другими столбцами в таблице. Это поможет гарантировать, что эти значения также будут храниться непрерывно, улучшая сжатие.
Операции
GROUP BYиORDER BYдля столбцов в сортировочном ключе могут быть более эффективными по памяти.
При идентификации подмножества столбцов для сортировочного ключа, объявите столбцы в определенном порядке. Этот порядок может значительно повлиять как на эффективность фильтрации по вторичным ключевым столбцам в запросах, так и на коэффициент сжатия для файлов данных таблицы. В общем, лучше всего упорядочивать ключи в порядке возрастания кардинальности. Это следует сбалансировать с тем фактом, что фильтрация по столбцам, которые возникают позже в сортировочном ключе, будет менее эффективной, чем фильтрация по столбцам, которые появляются раньше в кортеже. Учитывайте эти поведения и рассматривайте свои шаблоны доступа (и, что наиболее важно, проверяйте варианты).
Пример
Применяя вышеописанные рекомендации к нашей таблице posts, давайте предположим, что наши пользователи хотят выполнять аналитику, фильтруя по дате и типу поста, например:
"Какие вопросы получили наибольшее количество комментариев за последние 3 месяца".
Запрос на этот вопрос, используя нашу предыдущую таблицу posts_v2 с оптимизированными типами, но без сортировочного ключа:
Запрос здесь очень быстрый, даже несмотря на то, что все 60 миллионов строк были линейно просканированы - ClickHouse просто быстр! :) Вы должны поверить, что сортировочные ключи имеют значение на ТБ и ПБ масштабе!
Давайте выберем столбцы PostTypeId и CreationDate в качестве наших сортировочных ключей.
Возможно, в нашем случае мы ожидаем, что пользователи всегда будут фильтровать по PostTypeId. У этого ключа кардинальность 8 и он представляет собой логический выбор для первого элемента в нашем сортировочном ключе. Учитывая, что фильтрация по дате в границах будет достаточно (это все еще позволит выгодно использовать фильтры даты/времени), мы используем toDate(CreationDate) в качестве второго компонента нашего ключа. Это также создаст меньший индекс, так как дату можно представить 16, что ускорит фильтрацию. Наша окончательная запись ключа - это CommentCount, чтобы помочь найти посты с наибольшим количеством комментариев (последняя сортировка).
Для пользователей, интересующихся улучшениями сжатия, достигаемыми с использованием конкретных типов и соответствующих сортировочных ключей, смотрите Сжатие в ClickHouse. Если пользователи хотят дополнительно улучшить сжатие, мы также рекомендуем раздел Выбор правильного кодека сжатия столбцов.
Далее: Техники моделирования данных
На данный момент мы мигрировали только одну таблицу. Хотя это позволило нам ввести некоторые основные концепции ClickHouse, большинство схем, к сожалению, не так просты.
В других руководствах, перечисленных ниже, мы исследуем ряд техник для перестройки нашей более широкой схемы для оптимизации запросов ClickHouse. На протяжении этого процесса мы стремимся, чтобы Posts оставалась нашей центральной таблицей, через которую выполняется большинство аналитических запросов. В то время как другие таблицы все еще могут запрашиваться по одиночке, мы предполагаем, что большинство аналитики будет выполняться в контексте posts.
В этом разделе мы используем оптимизированные варианты наших других таблиц. Несмотря на то, что мы предоставляем схемы для них, ради краткости мы опускаем принятые решения. Эти решения основаны на правилах, описанных ранее, и мы оставляем вывод решений на усмотрение читателя.
Следующие подходы все направлены на минимизацию необходимости использования JOIN'ов для оптимизации чтения и улучшения производительности запросов. Хотя JOIN'ы полностью поддерживаются в ClickHouse, мы рекомендуем использовать их экономно (2-3 таблицы в запросе JOIN - это нормально) для достижения оптимальной производительности.
ClickHouse не имеет понятия внешних ключей. Это не запрещает соединения, но означает, что ссылочная целостность остается на уровне управления пользователем в приложении. В OLAP системах, таких как ClickHouse, целостность данных часто управляется на уровне приложения или во время процесса приема данных, а не контролируется самой базой данных, что накладывало бы значительные накладные расходы. Этот подход позволяет большей гибкости и более быстрой вставке данных. Это соответствует акценту ClickHouse на скорости и масштабируемости запросов на чтение и вставку с очень большими наборами данных.
Чтобы минимизировать использование JOIN'ов во время запросов, у пользователей есть несколько инструментов/подходов:
- Денормализация данных - Денормализуйте данные, комбинируя таблицы и используя сложные типы для не 1:1 отношений. Это часто включает перемещение любых соединений с времени запроса на время вставки.
- Словари - Уникальная функция ClickHouse для обработки прямых соединений и поиска по ключу.
- Инкрементные материализованные представления - Функция ClickHouse для переноса затрат вычислений с времени запроса на время вставки, включая возможность инкрементного вычисления агрегатных значений.
- Обновляемые материализованные представления - Похожие на материализованные представления, используемые в других продукт